
0 просмотренных постов скрыто



Dub Studio — бесплатный локальный «CapCut для ИИ-дубляжа»: переозвучивает видео на 6 языков с клоном голоса
Опенсорсный «CapCut для ИИ-дубляжа»: берёт любое короткое видео и переозвучивает его на другой язык — полностью локально, на своей видеокарте, бесплатно и без единой загрузки в облако.
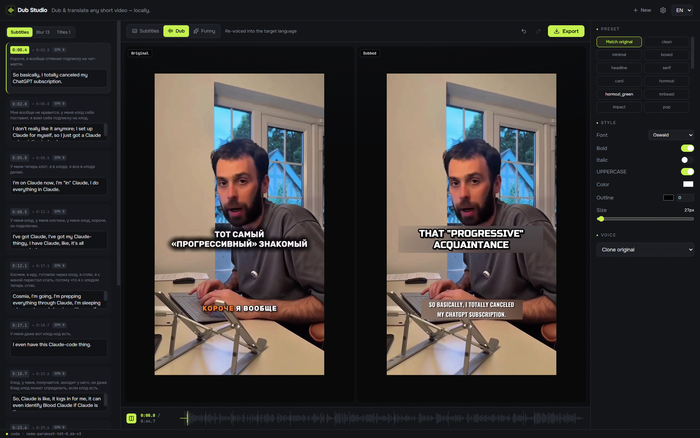
Авто-анализ делает первый проход — распознаёт речь, разделяет спикеров, переводит и считывает текст прямо на экране. Дальше ты садишься в живой редактор с превью «оригинал ↔ дубляж» бок о бок и правишь каждую реплику, голос, субтитр, плашку и заголовок. Под капотом — Parakeet для распознавания, Gemma-4 для перевода и зрения, Qwen3-TTS для речи.
Что умеет: клонирует голос оригинала (или раскидывает разные голоса по спикерам), локализует надписи прямо на месте, закрывает вшитые субтитры маской-блюром, настраивает стиль субтитров в реальном времени, диаризует несколько спикеров через NVIDIA Sortformer.
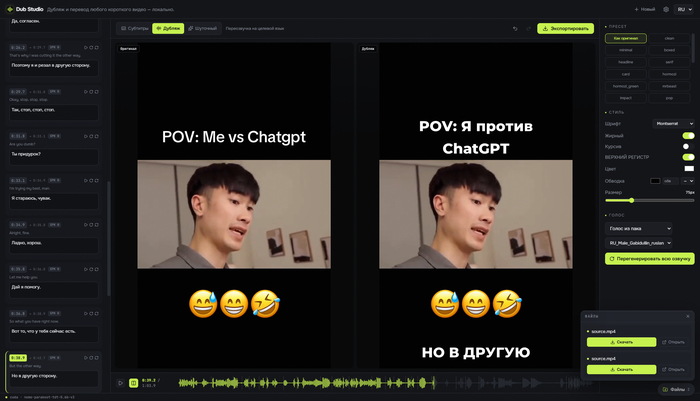
Есть даже Funny-режим, где Gemma переписывает сценарий и переозвучивает по-новому. Дубляж в EN / RU / ZH / ES / PT / FR, интерфейс на 6 языках, всё крутится в одном процессе офлайн.
Запуск: на Windows с NVIDIA — склонировать репо, прогнать install.bat и run.bat (путь без кириллицы и пробелов). На Linux / macOS / AMD / CPU — в один клик через Pinokio. Нужна видеокарта от 12 ГБ VRAM и ~30 ГБ на диске; модели качаются сами при первом запуске.
Ниже — две демки «оригинал → дубляж»: каждый раз сначала исходное видео, потом переозвучка.
🔗 GitHub: timoncool/dub-studio — если зайдёт, поставьте звезду, другим будет проще найти проект.
Так же доступна установка через Pinokio.
👾 НЕЙРО-СОФТ ● Репаки и портативки — делаем нейросети доступнее.
Показать полностью
2
7

Deus vult
Продолжаю эксперименты с дубляжом. Пока не удаётся полностью избавиться от остаточных артефактов.
Показать полностью

Битва нейросетей-озвучки: какой TTS лучший для русского дубляжа, честный тест
Делаю пайплайн автодубляжа: на входе англоязычный ролик — на выходе русская озвучка тем же голосом. Сердце такого пайплайна — нейросеть клонирования голоса (voice-clone TTS). Главный вопрос: какую взять?

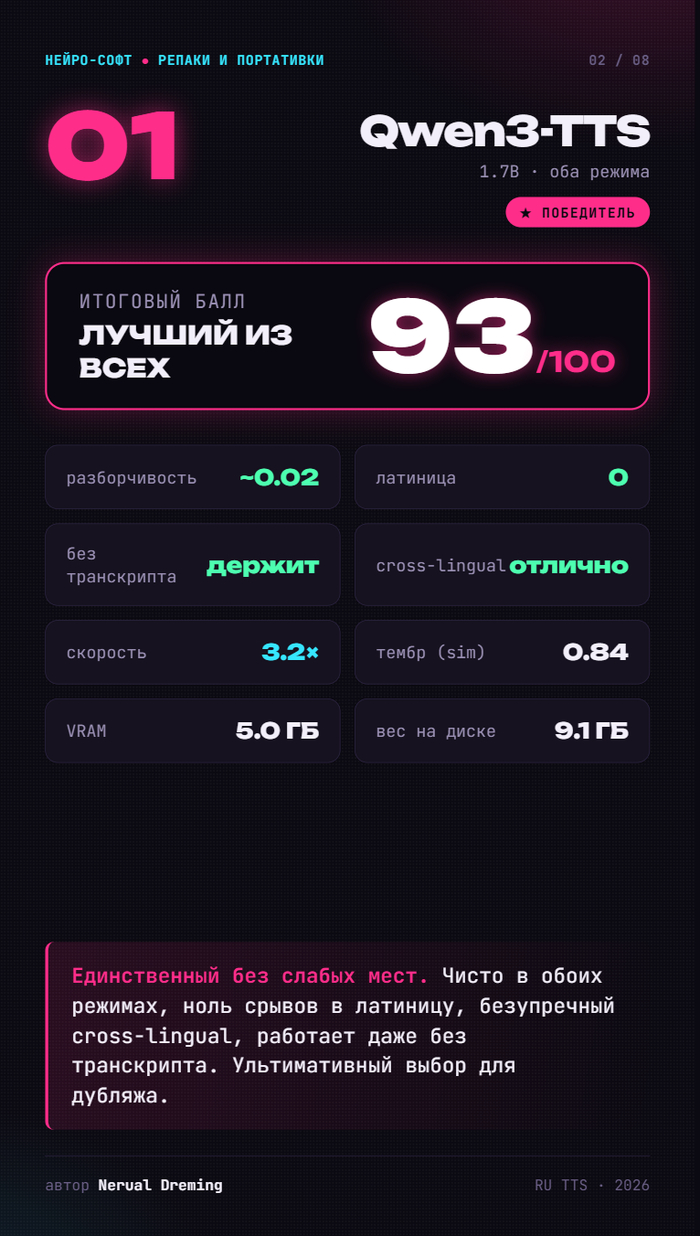
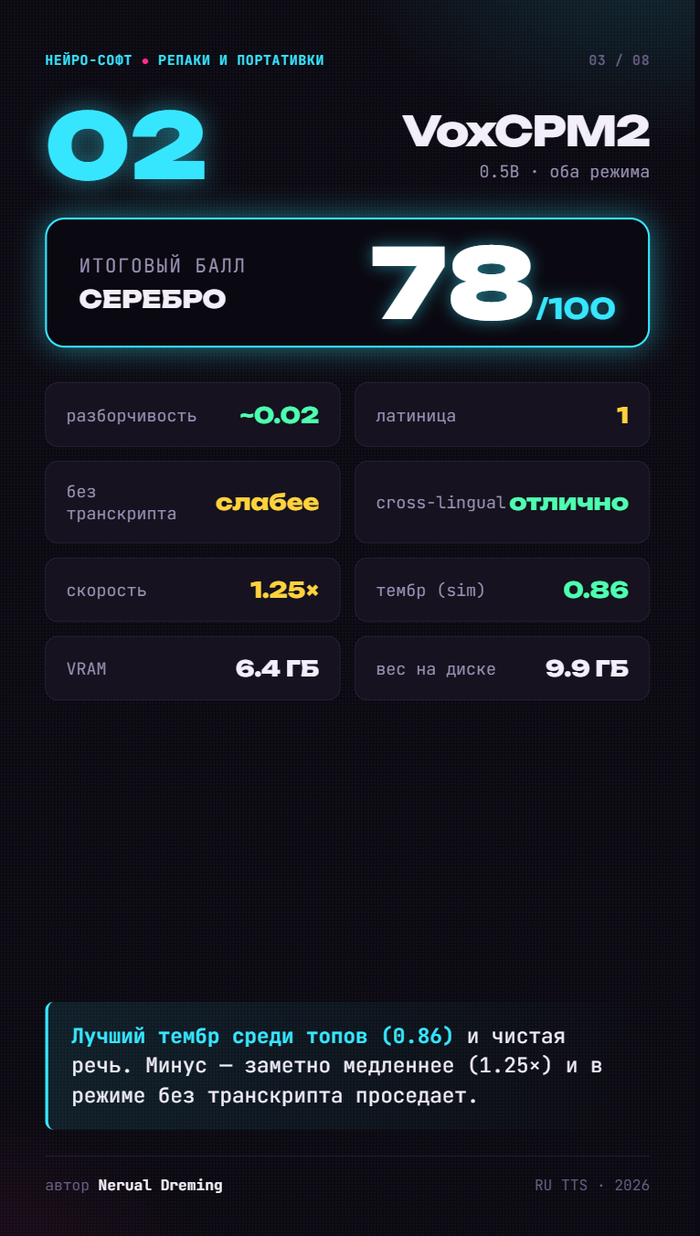
Можно ткнуть в первую попавшуюся с хайпом. А можно собрать топовые движки и устроить им честную битву на одинаковых условиях. Выбрал второе — прогнал финалистов через 627 семплов. Итоговый рейтинг — в карусели ниже, а вся подноготная (с чего начинали, кого выгнали и почему) — под ней.
Как собирал участников
Брал не наугад, а по реальным лидербордам (TTS Arena, Artificial Analysis) — только свежие флагманы. Часть кандидатов отсеялась сразу на входе: VibeVoice умеет только стриминг, OpenAudio S1 — прошлогодний, IndexTTS-2 — русский сломан, Step-Audio — только англ/кит. Осталось 8 движков для реального прогона.
Методология
Каждому движку — 114 фраз, всего 627 семплов. Тесты: русский и английский, длинные реплики, числа (прописью и цифрами), аббревиатуры (СДВГ, ОКР), иностранные слова, имена, скороговорки, смесь языков. И главное — cross-lingual: английский голос читает русский текст. Это и есть дубляж.
Оценивал на слух, семантически: засчитано всё, что произнесено верно. Если распознавалка записала «десять» как «10», а «Stable Diffusion» как «стейбл дифьюжн» — это её косяк, а не движка: зритель-то слышит правильно. Метрики: разборчивость, похожесть голоса, утечка латиницы, скорость, VRAM, вес на диске. Итоговый балл взвесил под задачу дубляжа.
Двоих выгнали сразу
После предварительного прогона вылетели двое:
dots.tts — на женском голосе разваливался: вместо русского текста выдавал английскую кашу или просто тишину. Плюс самый медленный. На вылет.
Chatterbox — умеет только режим без транскрипта, говорит с заметным акцентом, по сумме не конкурент. Тоже за борт.
Осталось 6 финалистов — детально по каждому в карусели выше, тут коротко:
Финалисты
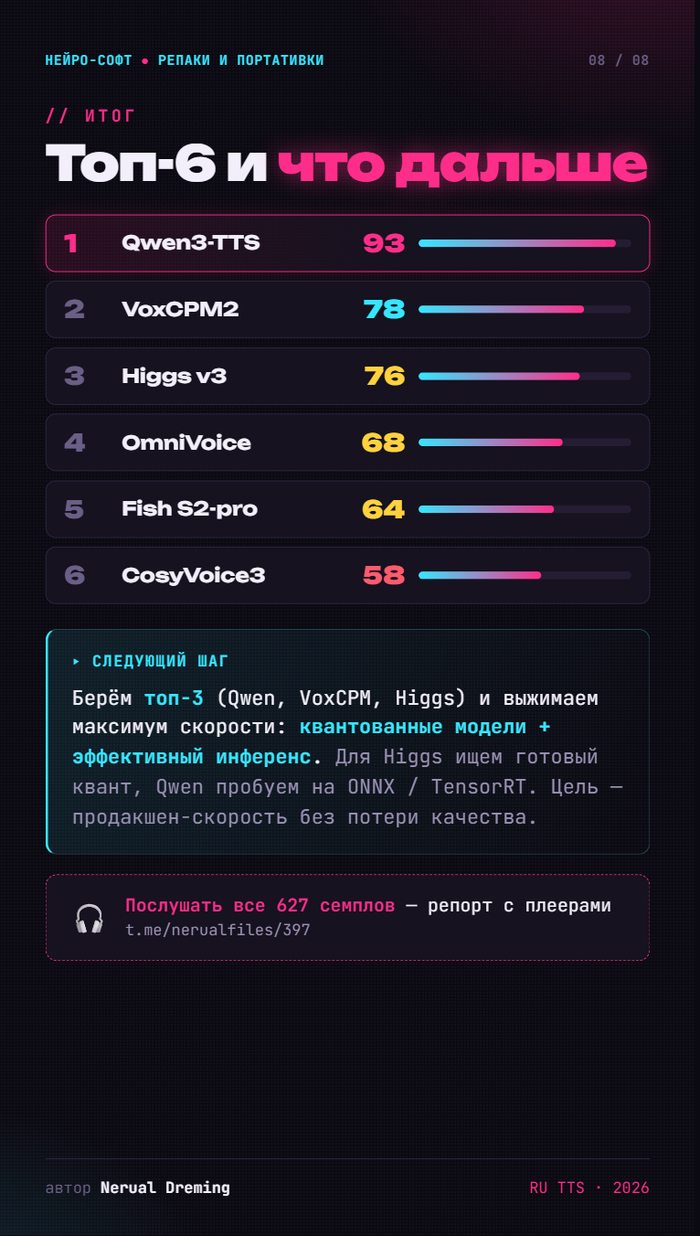
🥇 Qwen3-TTS — 93/100. Чемпион. Единственный без слабых мест: чистая речь и с транскриптом, и без, ноль срывов в латиницу, безупречный cross-lingual, быстрый. Его и берём.
🥈 VoxCPM2 — 78. Лучший тембр среди топов, чистая речь. Минус — медленный и без транскрипта проседает.
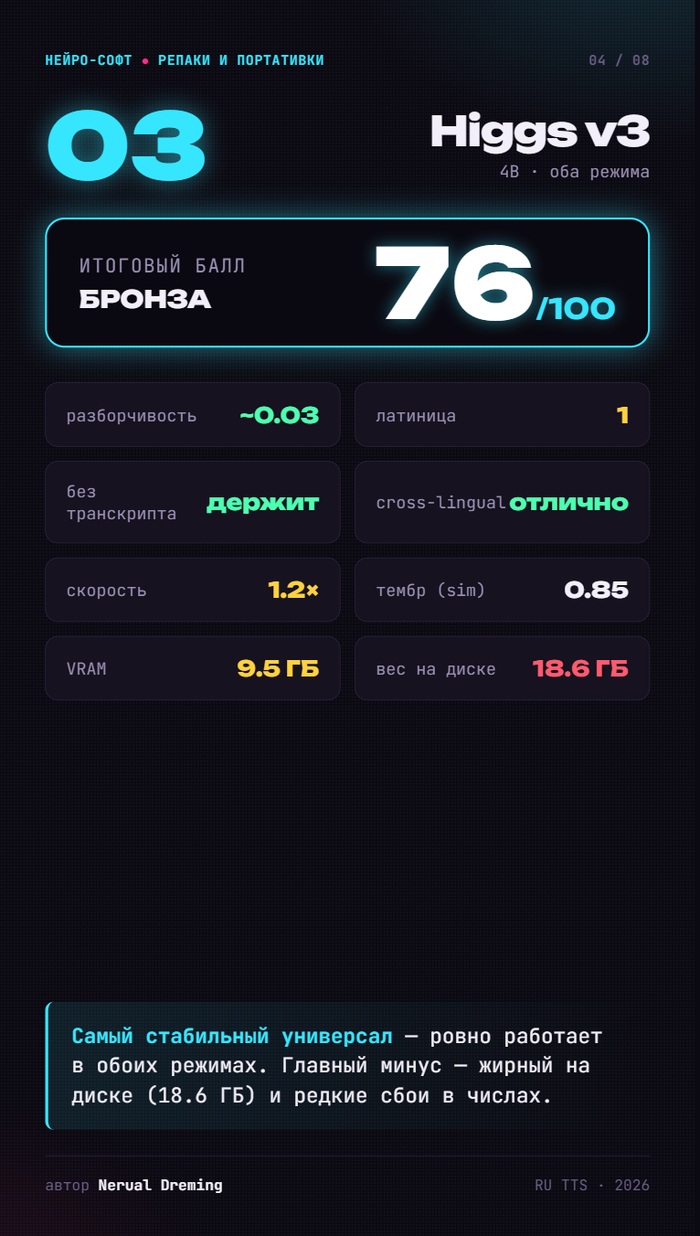
🥉 Higgs v3 — 76. Самый стабильный универсал. Главная беда — 18.6 ГБ на диске.
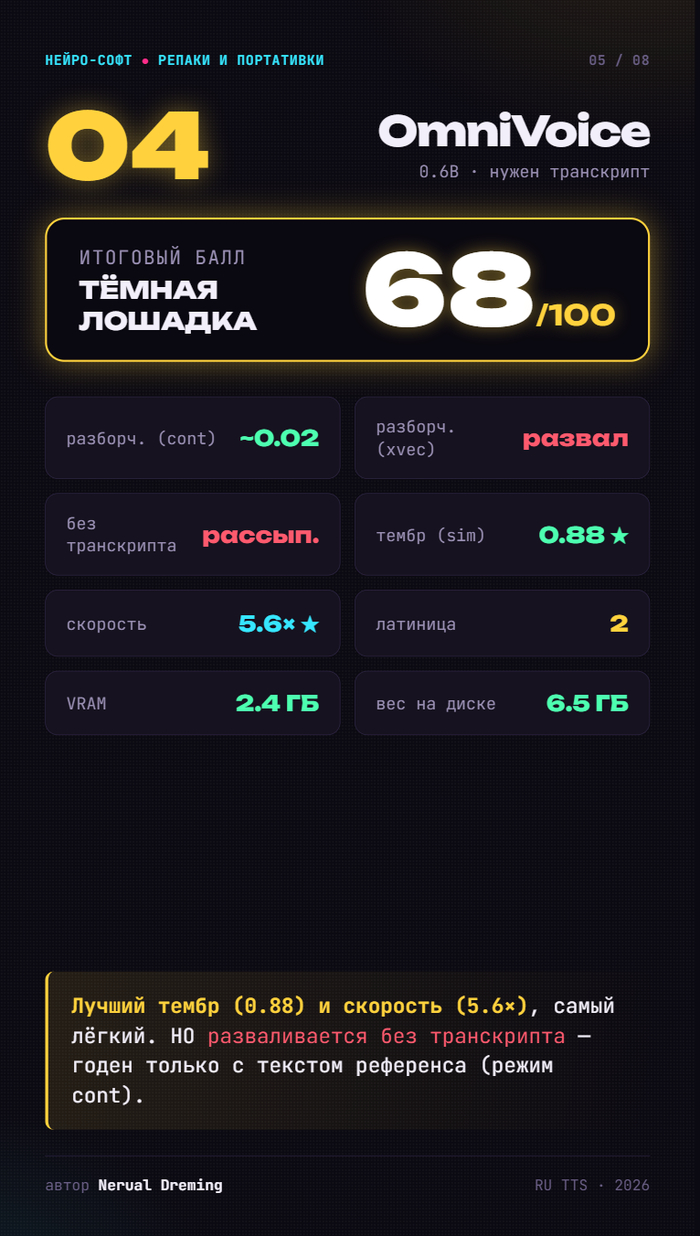
OmniVoice — 68. Тёмная лошадка: лучший тембр (0.88) и самый быстрый (×5.6 от реалтайма), легчайший. НО разваливается без транскрипта — годен только с текстом референса.
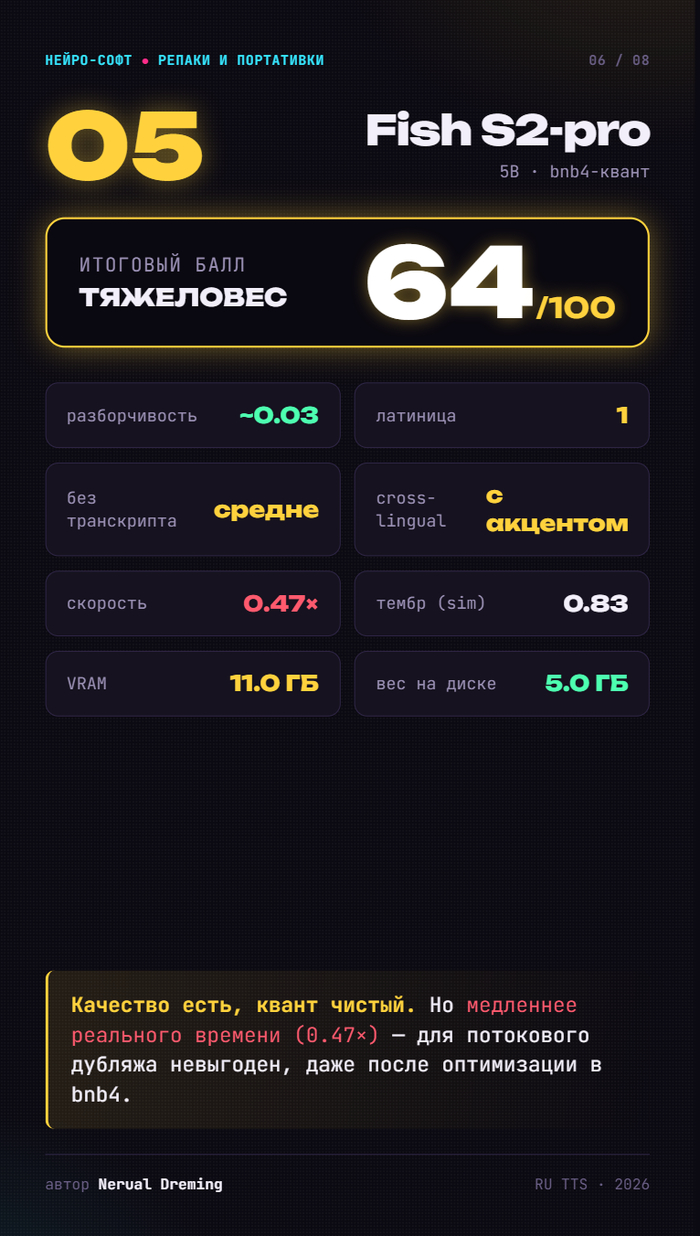
Fish S2-pro — 64. Качество есть, но медленнее реального времени даже после оптимизации. Для потока невыгоден.
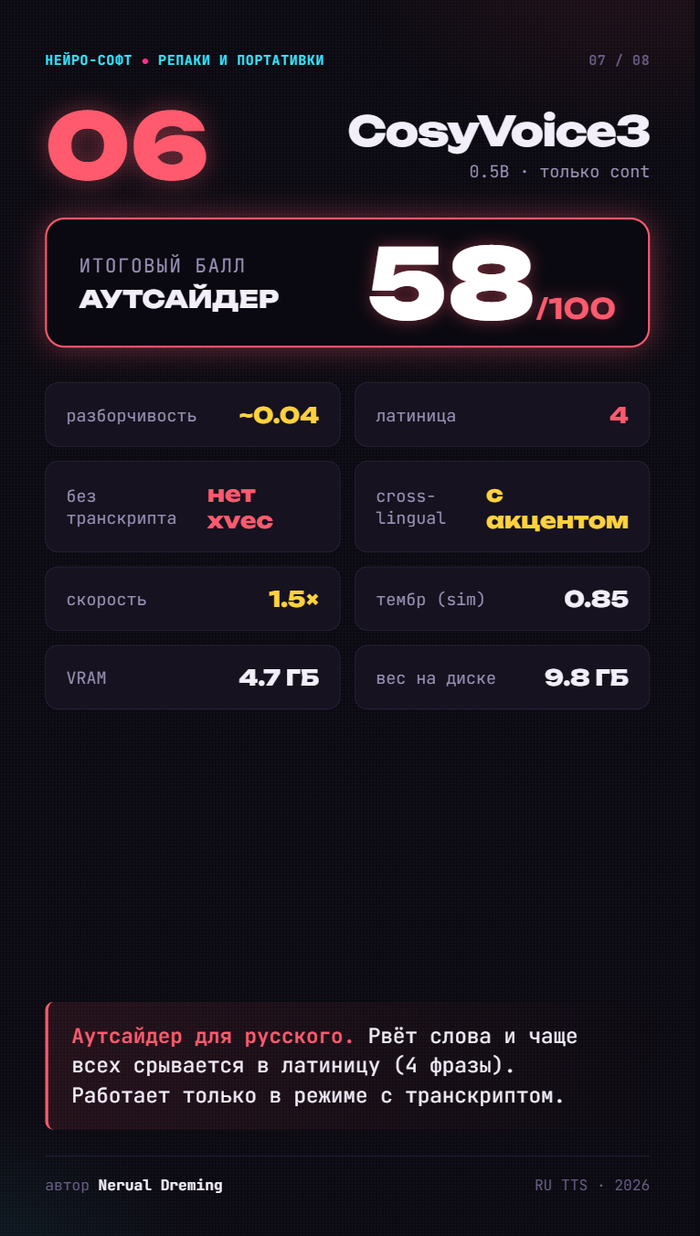
CosyVoice3 — 58. Аутсайдер для русского: рвёт слова и чаще всех срывается в латиницу.
Подводные камни (для технарей)
Fish в полной версии не влезал в 24 ГБ видеопамяти — распухал KV-кэш. Взял квантованную bnb4, сверил с полной по качеству (A/B) — квант оказался чистым.
CosyVoice пробовал ускорить через GGUF — и женский голос зациклился в 82 секунды мусора. Оказалось, баг самого тракта запуска (не доходит до токена остановки), а не квантизации.
Главная ловушка — распознавалка пишет англицизмы кириллицей. Чуть не записал кучу правильных озвучек в брак, пока не пересмотрел каждый транскрипт глазами.
Что дальше
Беру топ-3 (Qwen, VoxCPM, Higgs) и выжимаю максимум скорости: квантованные модели + эффективный инференс. Для Higgs ищу готовый квант, Qwen пробую на ONNX / TensorRT. Цель — продакшен-скорость без потери качества.
🎧 Хотите послушать все 627 семплов сами — собрал отдельный репорт с плеерами: t.me/nerualfiles/397
Это первая часть. В следующей — оптимизирую топ-3 под продакшен: квантованные модели, ONNX, TensorRT — и замерю реальный прирост скорости без потери качества. Будет интересно.
Мой канал: НЕЙРО-СОФТ ● РЕПАКИ И ПОРТАТИВКИ.
Показать полностью
8
Зависимость
Я решил попробовать дубляж и хотел бы услышать ваше мнение: работать ли дальше в этом направлении (я знаю, что мне ещё практиковаться и практиковаться) или оставить голос оригинала? Панамку, традиционно, приготовил.
Показать полностью