


Я и ИИ



Пытаюсь сейчас Zabbix установить, а так как я эникей, то пользуюсь промт- инжинирингом бессовестно.
*возможно баян.
Показать полностью
3
Пытаюсь сейчас Zabbix установить, а так как я эникей, то пользуюсь промт- инжинирингом бессовестно.
*возможно баян.
Вынос со скандалом Bcachefs из mainline-ядра Linux в конце 2025 года (начиная с релиза 6.18) проект не похоронил. Напротив, это явно подстегнуло мейнтейнера к жесткой дисциплине. Спустя 7 месяцев проект перешел на DKMS-модель и официально снял статус experimental.
Развернул тестовую ВМ в Proxmox, чтобы посмотреть на эксплуатационный UX: как ставится, как ведет себя при отказе дисков и стоит ли тащить в homelab или прод.
Дисклеймер. Это синтетические тесты, а не академический бенчмарк (на виртуалке поверх ZFS тестировать скорость - такое себе). Цель - проверить работу базовых функций, диагностику и поведение при аварии.
Тест проводился на Ubuntu 26.04 с ядром 7.0.0-22-generic. Штатного модуля в ядре дистрибутива нет, так что идем в официальный репозиторий за DKMS:
# Добавляем репозиторий apt.bcachefs.org (unstable / bcachefs-tools-release) и затем ставим всю обвязку
sudo apt install bcachefs-tools bcachefs-kernel-dkms fio btrfs-progs
По итогу получаем собранный модуль (bcachefs.ko.zst версии 1.38.6), и dmesg ожидаемо сыплющий ворнингами про tainting kernel и verification failed. Ну это просто надо иметь ввиду - теперь вы живете на внешнем модуле, и при каждом обновлении ядра нужно будет пристально следить за DKMS.
bcachefs: loading out-of-tree module taints kernel
bcachefs: module verification failed: signature and/or required key missing - tainting kernel
bcachefs: filldir64 fastpath disabled: struct layout unverified for this kernel
Первый тест был максимально тупой и прямолинейный:
Создать ФС на одном диске.
Смонтировать.
Записать файл 1 GiB и 5000 мелких файлов.
Запустить usage/scrub.
Размонтировать и выполнить offline check.
Для Bcachefs:
sudo bcachefs format -f -L bcf_single /dev/sdb
sudo mount -t bcachefs -o noatime /dev/sdb /mnt/bcf
sudo bcachefs fs usage -h -a /mnt/bcf
sudo bcachefs scrub /mnt/bcf
sudo bcachefs fsck -n -f /dev/sdb
Для Btrfs:
sudo mkfs.btrfs -f -L btr_single /dev/sdc
sudo mount -t btrfs -o noatime /dev/sdc /mnt/btr
sudo btrfs filesystem usage -T /mnt/btr
sudo btrfs scrub start -B /mnt/btr
sudo btrfs check --readonly /dev/sdc
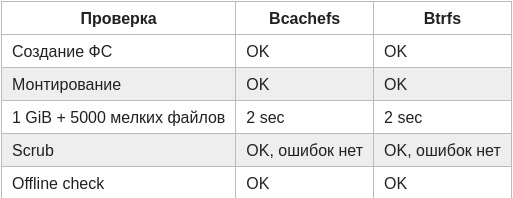
На этом этапе всё скучно, единственная практическая ценность тут - набор команд для создания ФС, может кому пригодится как шпаргалка.
Можно еще отдельно сказать про команды Bcachefs. Они непривычны, но в целом на удивление логичны: вместо mkfs.bcachefs используется bcachefs format, диагностика идёт через bcachefs fs usage, проверка через bcachefs fsck.
Для проверки сжатия использовал простой набор:
zero-512m.bin, 512 MiB нулей.
random-256m.bin, 256 MiB случайных данных.
Bcachefs создавалась сразу с zstd:
sudo bcachefs format -f -L bcf_zstd --compression=zstd /dev/sdb
Btrfs монтировалась с compress=zstd:
sudo mount -t btrfs -o noatime,compress=zstd /dev/sdc /mnt/btr
У Bcachefs понравилась отдельная секция в fs usage:

Итоговое использование места:
Bcachefs - около 283 MiB
Btrfs - около 274 MiB
Обе ФС отработали отлично (нули сжали, рандом пропустили). Разница в несколько мегабайт тут не имеет особого смысла.
Из интересного - у Bcachefs утилита fs usage выдает шикарную и очень наглядную статистику по сжатым/несжимаемым данным прямо в консоль.
Снапшоты проверял простым бытовым сценарием:
Создать subvolume.
Записать state.txt со значением original.
Создать read-only snapshot.
В живом subvolume поменять файл на changed.
Прочитать файл из snapshot.
Bcachefs:
bcachefs subvolume create /mnt/bcf/subv
bcachefs subvolume snapshot -r /mnt/bcf/subv /mnt/bcf/snap1
Btrfs:
btrfs subvolume create /mnt/btr/subv
btrfs subvolume snapshot -r /mnt/btr/subv /mnt/btr/snap1
Результат у обеих ФС одинаковый:
live=changed
snapshot=original
Здесь ноль сюрпризов. Снапшоты работают так, как от CoW-ФС и ожидаешь.
Теперь к цифрам. Ещё раз: это синтетические тесты внутри одного сомнительного стенда.
Параметры fio:
single disk
без сжатия
sequential read/write: bs=1M, size=2G
random write: bs=4k, numjobs=4, iodepth=16, runtime=30
Первые три строки ниже - это fio. Создание и удаление 10000 мелких файлов замерялись отдельно обычным shell-сценарием: создание дерева файлов и последующий rm -rf этого дерева.
Результаты:
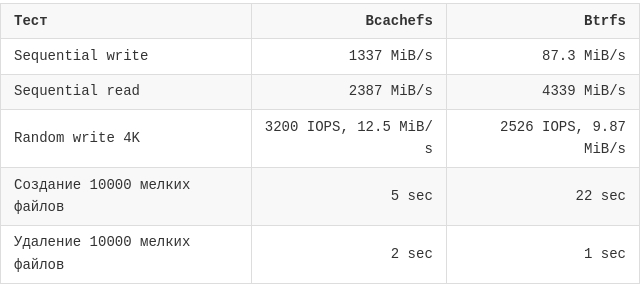
На этом стенде Bcachefs заметно быстрее на последовательной записи, random write 4K и создании мелких файлов. Btrfs, наоборот, быстрее на последовательном чтении и чуть быстрее удаляет дерево мелких файлов.
Само собой всё это автоматически не приводит нас к выводу, что Bcachefs быстрее Btrfs. Всё таки подложка в виде Proxmox/ZFS может сильно влиять на такие цифры. Но как лабораторный результат - как минимум любопытно.
Отдельный нюанс: во время нагрузки у Bcachefs в dmesg появилась строка:
bcachefs (sdb): bch2_journal_flush_seq stuck? Waited 10s for seq 32
После этого ФС нормально размонтировалась и прошла проверки. Но при эксплуатации это сообщение нельзя просто игнорировать. Его стоит отдельно разбирать при повторных тестах.
Одна из причин вообще смотреть на Bcachefs - обещание функциональности уровня современных CoW-ФС с более гибкой моделью устройств.
Bcachefs с двумя копиями данных и метаданных создаётся так:
bcachefs format -f -L bcf_raid1 --replicas=2 /dev/sdb /dev/sdc
После записи 512 MiB полезной нагрузки bcachefs fs usage показал ожидаемую репликацию:
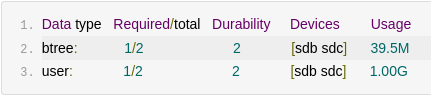
Btrfs RAID1 создавался привычно:
mkfs.btrfs -f -d raid1 -m raid1 -L btr_raid1 /dev/sdb /dev/sdc
У него всё ожидаемо отображается через Data ratio: 2.00 и Metadata ratio: 2.00.
Нюанс в терминологии: у Bcachefs модель --replicas=2 читается проще. Мы описываем желаемое количество копий, а не выбираем отдельные RAID-профили для data и metadata. Для админа это вполне приятная деталь.
Ну и само собой важная часть для любой multi-device ФС нифига не красивая таблица fio, а поведение при отказе.
Сначала пробовал имитировать отказ изнутри гостевой ОС через /sys/block/*/device/delete и device/state=offline. В этой ВМ метод оказался ненадёжным: устройство либо оставалось видимым, либо состояние быстро возвращалось в running.
Поэтому финальный тест делал через QMP hot-unplug на уровне Proxmox/QEMU. Постоянную конфигурацию ВМ не менял, удалял только live-устройство.
Bcachefs
Сценарий:
Bcachefs на /dev/sdb и /dev/sdc.
Форматирование с --replicas=2.
Запись 256 MiB payload.
QMP device_del scsi2, то есть удаление второго диска.
Проверка чтения старого файла и запись нового файла.
После hot-unplug /dev/sdc исчез из lsblk. Чтение и запись продолжили работать:
/mnt/bcf/payload.bin: OK
-rw-rw-r-- 1 user user 20 ... /mnt/bcf/after-qmp-hotunplug.txt
Диагностика Bcachefs показала, что часть метаданных уже требует восстановления реплик:
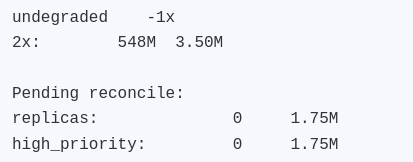
В dmesg появились ожидаемые ошибки по удалённому устройству:
bcachefs: error writing btree node ... sdc io: BLK_STS_OFFLINE
bcachefs (sdc): offline from block layer
bcachefs: error writing btree node ... sdc io: BLK_STS_REMOVED
Практический вывод: ФС осталась рабочей, данные читались, новая запись прошла. При этом состояние явно деградировало и требует дальнейшего reconcile/восстановления. Собственно, именно это и хотелось увидеть от теста.
Btrfs
Для Btrfs аналогичный сценарий делал на другой паре дисков:
Btrfs RAID1 на /dev/sdd и /dev/sde.
Так же запись 256 MiB payload.
QMP device_del scsi4.
Проверка чтения и запись нового файла.
После удаления /dev/sde ФС тоже продолжила работать:
/mnt/btr/payload.bin: OK
-rw-rw-r-- 1 user user 20 ... /mnt/btr/after-qmp-hotunplug.txt
btrfs filesystem usage -T показал missing device:
WARNING: failed to get device size for /dev/sde: No such file or directory
Device missing: 20.00GiB
В dmesg появились ошибки записи на удалённое устройство:
BTRFS error (device sdd): bdev /dev/sde errs: wr 1, rd 0, flush 0, corrupt 0, gen 0
BTRFS warning (device sdd): lost super block write due to IO error on /dev/sde (-5)
BTRFS error (device sdd): error writing primary super block to device 2
В этом конкретном сценарии обе ФС повели себя адекватно: RAID1-подобная конфигурация пережила потерю одного диска на живую, данные остались читаемыми, запись продолжилась.
Понравилось в Bcachefs:
bcachefs fs usage -h -a очень информативен.
Хорошо видно data/metadata, compression, btree и состояние устройств.
Модель --replicas=2 читается проще, чем отдельные профили -d raid1 -m raid1.
Снапшоты и subvolume-команды выглядят логично.
Потерю одного устройства при репликации ФС пережила.
Минусы:
Вместо нормальной поставки в составе ядра - поставляется как DKMS-модуль со всеми вытекающими (вообще надо было постараться настолько сильно выбесить мейнтейнеров ядра своим стилем разработки, чтоб тебя со скандалом вып*здили из mainline)
В dmesg был warning про bch2_journal_flush_seq stuck.
Сценарий возврата или замены диска после hot-unplug надо тестировать отдельно.
У Btrfs главный плюс скучный, но весомый: он давно есть в дистрибутивах, хорошо документирован, привычен и в принципе практически стабилен.
Bcachefs после снятия experimental уже имеет смысл тестировать в homelab.
В базовых сценариях ФС отработала нормально: создание, монтирование, scrub/fsck, сжатие, снапшоты, multi-device.
На этом стенде Bcachefs хорошо выступила на записи и мелких файлах, но это синтетические тесты.
Потерю одного диска при --replicas=2 Bcachefs пережила: данные читались, запись продолжалась, диагностика показала деградацию.
Если резюмировать, то основные вопросы пока не столько к самой ФС, сколько к эксплуатационной обвязке: DKMS, обновления ядра, загрузка модуля и восстановление после отказов.
ИМХО, для лаборатории, тестового NAS, домашнего стенда и удовлетворения инженерного любопытства - да, Bcachefs уже интересно гонять. Для продакшена или единственной копии важных данных - только после собственных аварийных тестов и с нормальными бэкапами.

Чуть больше месяца назад я впервые рассказал об IncidentRelay, open-source и self-hosted системе для дежурств, маршрутизации алертов и эскалаций.
В первой версии основная цепочка уже работала:
Monitoring -> Route -> On-call -> Notification -> ACK / Resolve
С тех пор проект добрался до v1.0.21-beta. Цепочка стала длиннее, но пользоваться системой стало проще. В отличие от некоторых корпоративных процессов, здесь усложнение действительно пошло на пользу.
Не буду пересказывать весь changelog. Расскажу о нескольких изменениях, которые сильнее всего повлияли на продукт.
Простая ротация выглядит красиво: несколько инженеров по очереди дежурят сутки. Потом в неё приходят рабочие часы, выходные, отпуска, разные часовые пояса и человек, который только в пятницу вечером вспоминает, что завтра улетает.
Поэтому в IncidentRelay появились многослойные ротации. У каждого слоя могут быть свои:
участники и приоритет;
временные ограничения;
часовой пояс;
правила передачи смены.
Поверх расписания работают временные замены. Календарь показывает уже итоговый результат после применения всех слоёв и overrides.
Расписание можно подключить к Google Calendar, Outlook, Apple Calendar и другим клиентам через ICS или read-only CalDAV. Пользователи также могут получать уведомления о предстоящих сменах.
Появился On-call Health. Он заранее ищет пустые слои, неактивных участников, разрывы в расписании, маршруты без получателя и проблемы с каналами уведомлений.
Лучше увидеть красный индикатор днём, чем обнаружить ночью, что единственный дежурный существует только в базе данных.
Одна проблема редко присылает одно аккуратное сообщение. Обычно сначала жалуется база, потом API, затем очередь, а через минуту к обсуждению присоединяется всё, у чего есть доступ к Alertmanager.
Теперь IncidentRelay умеет группировать связанные события по сервису, окружению, кластеру, имени алерта и другим labels.
Для группы можно:
задержать первое уведомление;
настроить периодические обновления;
выполнить ACK или Resolve сразу для всей группы;
объединить несколько групп вручную;
оставить комментарии и сохранить историю расследования.
Исходные алерты при этом не теряются. Дежурный получает одну развивающуюся историю вместо серии сообщений с одинаковым смыслом и разной пунктуацией.
Раньше IncidentRelay хорошо отвечал на вопрос «кому отправить алерт», но почти ничего не знал о самом объекте аварии.
Теперь в системе есть каталог сервисов. Для каждого сервиса можно задать владельцев, критичность, окружение, runbooks, ссылки, правила сопоставления с алертами и зависимости от других сервисов.
На основе зависимостей система показывает:
возможную первопричину;
затронутые сервисы;
путь распространения проблемы;
общий blast radius.
Также появилась аналитика: сгруппированные инциденты, объём сырых алертов, дедупликация, уровень шума и время реакции.
Это не замена observability-платформе. Задача скромнее: избавить дежурного от традиционного ритуала поиска актуального runbook среди wiki, старого чата и ссылки, которая «точно работала в прошлом квартале».
ACK сообщает, что алерт кто-то увидел. К сожалению, он не ремонтирует базу данных. Мы проверяли.
Поэтому в IncidentRelay появились:
приоритеты от P1 до P5;
автоматическое повышение приоритета по severity;
запрос дополнительных responders;
stakeholders и настройки их уведомлений;
комментарии и timeline;
maintenance windows.
Maintenance window можно привязать к группе, команде, сервису или маршруту. Во время работ система может отключить уведомления, не создавать новые инциденты или временно остановить эскалации.
Поддерживаются часовые пояса и повторяющиеся правила RFC 5545. Потому что любое простое окно обслуживания рано или поздно превращается в «каждый второй вторник, кроме праздников и последней недели квартала».
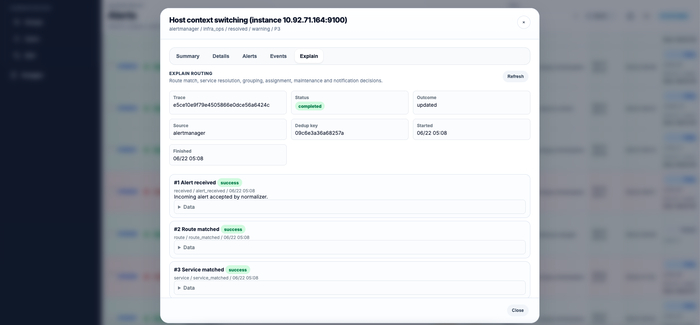
Самая заметная новая функция называется Alert Explain Trace.
Если алерт не дошёл или попал не в ту команду, больше не нужно вручную воспроизводить всю конфигурацию. IncidentRelay записывает этапы обработки входящего события.
В трассе видно:
Был ли принят payload.
Какой route совпал.
Какой service был найден.
В какую группу попал алерт.
Сработали ли silence или maintenance window.
Как выбрали дежурного.
Какие уведомления были отправлены или пропущены.
Интеграция получает trace_id, по которому результат можно открыть в UI или запросить через API.
Для self-hosted продукта прозрачность особенно важна. «Система решила именно так» звучит гораздо убедительнее, когда рядом есть список причин, а не только уверенный зелёный индикатор.
За месяц IncidentRelay вырос из маршрутизатора алертов в более связный workflow:
Alert -> Route -> Service -> Group -> Priority -> Escalation -> On-call -> Responders -> Notifications -> Resolution
Проект всё ещё находится в beta и активно развивается. Впереди новые интеграции, улучшение аналитики и более простая установка. Но уже сейчас система умеет не только разбудить дежурного, но и объяснить, почему выбрала именно его. В мире on-call это почти проявление вежливости.
Буду рад обратной связи и примерам реальных расписаний. Чем страннее график, тем полезнее тестовый сценарий.
Для ЛЛ: Отраслей в ИТ много, но далеко не все из них про деньги.
Длинное вступление, которое можно пропустить
В мире есть огромное количество «Дурки по МКБ» (Международная классификация болезней , текущая редакция 11). В разговорном русском и пикабушном (и мировом) известны зоошиза, инцелшиза, мужикдолженшиза, вакциношиза, и разные виды религиозного фанатизма, начиная от нью эйдж и заканчивая верой в социализм как филиал Царства Пресвитера Иоанна. Рядом с социализмом ходит и опенсорс (СПО) шиза, с ее «линукс бесплатный». Линукс бесплатный, а ресурсы под него все равно стоят денег. И люди для его поддержки тоже стоят денег.
Зоошиза сходу отбрасывает тот факт, что не дрессированные собаки кусаются, собаку надо нормально кормить, нормально дрессировать, нормально вакцинировать. Из коробки работает так себе.
СПО шиза сходу отбрасывают фактор денег и поддержки, как малозначимый. Что СПО надо крутить на нормальном железе (кормить), нормально настраивать (дрессировать), нормально обновлять (вакцинировать). Из коробки работает так себе.
Шпаргалка по общению с СПО-сектантами написана давно, спорить особо не о чем.
Нормальная рабочая собака - нормально работает.
Нормально настроенный сервис на Линукс – нормально работает.
Нормально делай – нормально будет.
Нужно понимать, что есть грань между визионерством и СПО шизой, любовью к собакам и зоошизой.
И, как это часто бывает, за пределами интернетов отношение к чему угодно куда как более простое.
— Собаки, ага. Это дед Доценко, — непонятно ответил Василич.
— Это дед, что ли, так лает? — изумился Вадим.
— Не, не дед. Собаки его, — успокоил Василич. — Пока только начало.
— Начало чего?
— Ну ему весной для развода собак из деревни привозят. Видишь ты, там клетухи стоят. Каждую собаку в свою клетуху садют. Он их потом спаривает, они щенков приносят, потом всё лето здесь на берегу жрут, что им бог пошлёт. А шлёт им бог траву, тину и морскую падаль всякую.
Кречмар Михаил. Береговой клиф
Однако, хватит отвлеченной теории.
Раньше я упоминал, что возможности современного железа где-то году в 2010 – 2015 наконец-то обогнали реальные потребности малого и среднего бизнеса. То есть, сейчас значимую часть проблем типа «тормозит» можно закрыть просто покупкой железа. Да, это дорого, но это понятные бизнесу затраты «на основные средства». Купил – включил – работает.
Причем (и комментаторы правы в этом вопросе), для большей части запросов малого и среднего бизнеса достаточно железа из 2020 года. Хватило бы и из 2015, но там уже будут проблемы с надежностью самих плат и иногда необходимостью перепайки «по мелочи». Мега-скорости на ватт подводимой мощности, и мега-концентрации «виртуалок на юнит в стойке» не будет, но она и не нужна.
Нет в «базовом ИТ» и каких-то тайных знаний про настройку в .env файле параметра dothebest TRUE. Есть проблема, что в русском сообществе пытаются писать литературу «как привыкли учить в ВУЗ, с кучей теории», в западном пишут инструкции «для ИТ колледжа».
Итог – «базовое ИТ» в мире западного образования занимало (часть курсов отменена):
1 неделя: базовый курс «железо, электричество, техника безопасности, кабеля».
1 неделя: базовый курс сетей, ICND1
4 недели: курсы Microsoft Technology Associate (MTA):
Windows Operating System Fundamentals – экзамен 349 (не сдают с 2022, замены нет)
Windows Server Administration Fundamentals – экзамен 365 (не сдают с 2022)
Networking Fundamentals – экзамен 366 (не сдают с 2022)
Security Fundamentals – экзамен 367 (не сдают с 2022)
Сейчас курсы заменены на тройку AZ-700, AZ-900, MS-900, но там чуть другой набор знаний.
Добавляете базовый курс по Linux, Linux Foundation Certified System Administrator (LFCS) – 16 учебных часов, и все – вы великолепны.
6-8 недель на всю учебу, если учиться без остановки по 6 часов в день, и вечером делать лабораторные работы и домашнюю работу.
12-16 недель, 3-4 месяца, занимаясь вечерами дома по 2-4 часа.
Причем, 70% из этих знаний вы использовать не будете, но вы никогда не узнаете, какие именно 70%.
Что это значит? Что курсы максимально упрощены, и их может пройти почти любой. Экзамены тоже максимально упрощены. Два года назад по другим экзаменам проходной балл дополнительно снижали.
Что это значит? Что это очень низкая квалификация, для получения которой много знаний не нужно.
Что это значит? Что таких работников много, они легко заменимы, и, значит, ДЕШЕВЫ.
Для Москвы это означает «зарплата на уровне курьера, 100-150 тысяч рублей в месяц».
В регионах РФ, наверное, «меньше 1000$».
Для мира это означает, что проще взять индусов на аутсорс. Можно «местных индусов». Можно «просто местных».
Индусы достаточно обученные, достаточно дешевые, и они уже тут. То есть первый уровень, это не дорога к «деньгам», особенно если вы сидите на этой позиции и не обучаетесь.
Дорога «не туда».
Проблема российского (и, местами, мирового) сообщества в том, что и «в РФ» и «вне РФ» на слуху наиболее громкие представители сообществ.
Смотри выше, кто громче всех выступает в защиту собак, и больше всего минусит за любое неприятное мнение.
Та же проблема с громко предлагаемыми решениями.
На примере систем хранения данных это будет выглядеть следующим образом:
Допустим, бизнес вырос (давно, или недавно) настолько, что хочет свое выделенное хранилище данных (документов, не говоря про data lake \ data warehouse).
Сначала это сетевая папка, на отдельном компьютере, иногда даже с дисками в программном или аппаратном рейде.
Программный рейд делается в Windows server «из коробки» уж не с 2000 ли версии сервера. Mdadm – 2001 год.
Distributed Replicated Block Device (DRBD) – LINBIT – 2001 год, и Philipp Reisner по прежнему пишет. И даже RDMA пишут, что включен.
Microsoft S2D делается на раз два начиная с Windows Server 2016.
Два компа, 4 диска (два загрузочных, два для данных), сеть, далее далее готово.
Какое решение «удобнее» с точки зрения скорости работы и скорости развертывания ? Очевидно, на Windows Server. Быстро разворачивается, быстро работает, легко поддерживать. Дорого (если лицензии на Datacenter покупать).
Какое решение «удобнее» с точки зрения экономии на лицензиях, если есть дешевые кадры?
Да тот же Linstor, ставится в одну команду:
apt install linstor-controller linstor-satellite linstor-client
Какое решение вам предложат «изи-онеры» - ставьте CEPH, это ИЗИ.
То, что там производительность падает в ноль, и ребилд вызывает боль, и для установки и настройки надо чуть больше команд, и с точки зрения бизнеса этот велосипед не нужен при мизерных объемах – будет проигнорировано.
В среднем бизнесе любят считать деньги, порты, и IOPS. Попробуйте посчитать, найдите калькулятор для CEPH.
В крупном бизнесе попросят продемонстрировать лист совместимости, для начала, и SLA для коммерческой поддержки, чтобы не держать в штате уникальных и дорогих специалистов.
Почему не предложат vitastor – я не знаю.
Почему не предложат купить самую дешевую дисковую полку и заниматься основной работой – тоже не понимаю. Ради «опыта на потом» ? Пару лет заниматься сложной интимной жизнью с CEPH и иметь уникальный опыт починки «путем восстановления из резервной копии», который без массы других знаний на рынке не нужен? Странный совет.
Исторические аналоги такого подхода есть.
У Тейлора есть пример, «как правильно копать лопатой, и почему». В том числе с примерами, что будет с зарплатой, если копать неправильной лопатой в неправильной команде. Если у вас есть абстрактное мышление, а оно должно быть в ИТ, вы легко переведете этот пример на ситуацию с 21 веком и современными лопатами. Включу Тейлора в список литературы на первое место, очень полезная книга по организации труда. До сих пор полезная. Потому что написана простым языком на простых примерах.
И, еще раз повторю.
ИТ-блок, с точки зрения бизнеса, это блок «расходы». Всегда блок «расходы». Даже для фирм по разработкам. Не проданная разработка не приносит денег. Пример – Мой офис.
ИТ в регионах массово «не нужно» выше уровня «посчитать зарплату и налоги в 1с». Исключения есть в достаточном количестве, чтобы про это поспорить, и нет в достаточном количестве, чтобы это показать в цифрах. Да, я знаю, что в регионах есть и ЦОД, и были центры компетенций и разработки – Новосибирск, Нижний Новгород, итд. Но .. можно сравнить массовый требуемый уровень ИТ с уровнем метро. Сравнить карту московского метро и омского метро.

Теперь про деньги, как без них
В онлайн обсуждениях в РФ уже много лет пишут про острый дефицит высококвалифицированных низкооплачиваемых кадров.
Опыт пузыря доткомов 1995 – 2000 и надувание ИТ в 2020-2023, с последующими массовыми увольнениями сотрудников (в мире началось где-то в 2023, в РФ началось где-то летом - осенью 2024), показывает, что нет никакого недостатка. Наоборот, есть избыток «кадров в ИТ».
При этом в РФ .. Тебе повезло, ты не такой как все - ты работаешь в офисе – пели еще в 2003 году.
На фоне многих других профессий, резкий рост «цифровизации» где-то на рубеже 2000, совпавший с ростом цен на нефть, и тогдашним наведением порядка, без кавычек и достаточно видимым, совпал с мировой цифровой революцией (доткомами), и сыгравшей ставкой Сороса «на РФ». Если кто-то не знает, именно фонд Сороса затащил катку «интернет в РФ» в середине 1990-х. (Я понимаю, что на эту фразу стриггерятся боты и придут писать не по теме, и ставить минусы).
Сегмент «ИТ и интернет» резко рванул вверх, и на фоне конкуренции между «всеми в РФ» и, чуть позже, на фоне конкуренции «запада и РФ» вплоть до кризиса 2008 года, вынудил работодателей повышать зарплаты до уровня «почти как в Европе». Где-то до 2007 года (плюс минус) кто-то (но не я) катался Кипр – Москва – Кипр чуть ли не по выходным.
Почему? На рынке труда не было массовой удаленной работы и настолько массовых индусов.
В 2013 году? Уже не так
Аудит сетевых логов в американской компании Verizon обнаружил поразительную вещь: один из ведущих специалистов компании постоянно держал открытое VPN соединение с китайскими серверами. Оттуда под его учётными данными в корпоративную сеть входили китайские программисты — и выполняли все рабочие задания. Эта удивительная история опубликована в корпоративном блоге Verizon
В 2025 году? Уже массово:
В США 40-летний Минь Фыонг Нгок Вонг (Minh Phuong Ngoc Vong) признал себя виновным в сговоре с целью совершения мошенничества. Более дюжины американских компаний, работающих по контракту с государственными учреждениями, в совокупности выплатили ему более $970 тыс. в качестве зарплаты за работу, которую он не делал, выяснило издание Law360.
https://www.cnews.ru/news/top/2025-04-16_vmesto_nanyatogo_udalenno
Сейчас?
«Знания» в ИТ не являются уникальными. Ценится опыт последних 3-5 лет, причем в новых отраслях, приносящих самую высокую прибыль. Даже если в новостях говорят про «ожидаемый пузырь на рынке ИИ».
Железо? Описано выше.
Бесплатные или дешевые открытые ИИ позволяют выполнять простые задачи даже неквалифицированному персоналу «без опыта» на уровне лучше, чем у меня. ИИ, и это так, пишет простой код лучше меня, решает простые задачи по разработке лучше меня. С ИИ можно накрутить в 3-5 раз больше простого кода, чем без него.
Рынок? Все мировые рынки ИТ в глубокой Ж, и европейский, и американский, и канадский. Про Австралию давно не узнавал. Дешевый сегмент «труда» завален дешевым предложением, дорогой сегмент труда разгребает последствия инвестиционного цикла ковидных лет, сокращая персонал. Средний сегмент завален ИИ скамом, разного вида. В том числе поддельным наймом, с ИИ собеседованием, где ты учишь ИИ, выступая как подходящий кандидат. То есть на тебе дообучают модель.
Рынок управления везде в точно такой же глухой Ж. Поголовно менеджмент жертвует производительностью труда в пользу имитации управляемости. Никуда не делись выгорание, теперь ускоренное ИИ и «новыми красноглазыми». ИИ дает отличный буст к выгоранию.
Получается, что деньги продолжают платить только там, где существует:
- реальная конкуренция за кадры
- реальный спрос, то есть подкрепленный деньгами
И даже в мире это очень небольшой, и очень высококвалифицированный сегмент, с огромными знаниями.
Получается очень интересная история, характерная для ИТ.
Не важно, в каком ты сегменте рынка «сейчас», если у тебя есть база. База – выше. Это одна и та же база и для системного администрирования, и для девопс, и для разработки, и для аналитики. Можно ее знать лучше, хуже, но какой ты разработчик, если из любого IDE не пушишь данные на гитхаб, откуда он раскатывается на домашний k3s?.
Почему? Потому что «прямо сейчас» зарождается новый сегмент рынка, на котором еще ни у кого нет знаний. Через 5 лет, может быть, выстрелят квантовые вычисления.
Или выстрелит фотоника, причем настолько, что весь кремний сразу можно будет списать, как за 10 лет после появления чипов – списали лампы.
На этом момент вы, конечно, вправе сказать «Григорий, ну какие 10 лет, о чем ты? Посмотрим.
Первая планарная монолитная интегральная схема (ИС) была продемонстрирована в 1960 году.
В 1964 году IBM 7094, IBM 7040 и СХД IBM 1301 были установлены в NASA. Без ламп.
В 1962 году в ракету Титан 2 ставили цифровой блок наведения ASC-15 (Advance System Controller Model 15)
В 1968 году модуль шифрования голосовой связи NESTOR KY-38 уже был сделан только на микросхемах и электромеханике.
Та же история в радио.
Рация AN/PRC-10 (1951) – ламповая. AN/PRC-25 (1962) – одна лампа. AN/PRC-77 (1968) – без ламп.
Ситуация не меняется. Новый сектор технологий возникает каждые лет 5, и за лет 10 он проходит путь от «никто не знает» до «родился мертвым» или до «используется везде».
Старые технологии при этом не умирают, а упрощаются и уходят на все более бытовой уровень.
И все более дешевый.
Что это значит? Что нужно постоянно смотреть на рынок, много читать, многому учиться. Подтягивать базу при возникновении пробелов «в базе».
И не бояться того, что было, есть, обязательно будет – бухтению дедов (включая меня), что надо бы сначала говна поесть, выучить все хоткеи для vi, а потом уже заниматься наноботами на блокчейне. А то, ишь, обколются своими агентами и распивают огуречный смузи.
Что еще важно понимать? Как бы это не звучало «не патриотично», но РФ отставала и отстает от западных технологий и трендов на 5-10 лет, а если брать в расчет военный и очень суровый энтерпрайз, то и на все 15-20. Примеры?
Машинное зрение. Точно не вспомню, но в 2012 – 2015 его уже активно тренировали в коммерческом мире (в военке с середины 1980-х).
Итог ? В мире в 2017 году появился Anduril Industries и Project Maven.
AI разных видов? В мире капитала Skype Translator, появился в тестах с декабря 2015 года.
В передовых отраслях всегда высокий спрос, но для реализации этого «высокого спроса» надо быть в рынке.
AI? Уже является «массовым продуктом». Все, что ниже по стеку? Тем более, давно массовые продукты.
Поэтому, наверное сейчас я бы для вкатывания выбрал смешанную тактику прохождения:
– изучение вариантов быстрого прохождения курсов на ютубе
- быстрое прохождение базы по максимально простому пути. Наверное, про это будет следующий текст, выбор самого простого пути. Open Shortest Path First, Dijkstra's, жадные и ленивые режимы, и прочее А.
- вкатывание само по себе.
Литература дополненная
Earn a Microsoft Technology Associate (MTA) certification
Получите сертификат Microsoft Technology Associate (MTA)
Microsoft Certified: Azure Network Engineer Associate
Study guide for Exam AZ-700: Designing and Implementing Microsoft Azure Networking Solutions
Linux Foundation Certified System Administrator (LFCS) Specialization
Linux Foundation Certified Systems Administrator – LFCS
The Time of Hardware RAID Controllers is Over
Becoming More Accessible to Windows Users
Как быстро установить и использовать Linstor в Kubernetes
Оригинал: утрачен, был тут: https://vitobotta.com/2019/08/07/linstor-storage-with-kubern...
What Are the Hardest Parts of Kubernetes to Learn?
со ссылкой на: Storage on Kubernetes: OpenEBS vs Rook (Ceph) vs Rancher Longhorn vs StorageOS vs Robin vs Portworx vs Linstor, Vito Botta
Выпущена версия Vitastor 3.0.14
Читать эти 6 книг нужно именно в таком порядке, по мере выхода книг.
Остальные читать в любом порядке.
1 Фредерик Уинслоу Тейлор . Принципы научного менеджмента
Удивительно, но по запросу «тейлор научная организация труда читать онлайн» книга будет не второй ссылкой, а четвертой.
2 «Мифический человеко-месяц, или Как создаются программные системы» (англ. The Mythical Man-Month: Essays on Software Engineering)
3 Deadline. Роман об управлении проектами
4 Проект Феникс. Роман о том как DEVOPS меняет бизнес к лучшему
5 Весь цикл «Рождение советской ПРО»: https://topwar.ru/user/Sperry/
Можно читать даже комментарии, где пишут, что автор ничего не понимает, либерал и вредитель.
Но, среди членов клуба зануд он считается опасным интеллектуалом.
6 Билл Гейтс. Бизнес со скоростью мысли
В systemd 261 подвезли сразу несколько вещей, от которых у старой школы снова начнёт подёргиваться глаз и гореть пердак: systemd-sysinstall, IMDSD и storagectl.
Самое вкусное тут, конечно, systemd-sysinstall. Это попытка сделать нативный установщик ОС прямо внутри systemd. Не графический мастер с кнопкой "далее-далее-готово", а низкоуровневый механизм, который умеет ставить систему по описанию: разметка, образы, загрузчик, нужные системные компоненты. То есть ещё один кусок жизненного цикла Linux-системы переезжает под крыло systemd.
И это уже не просто "инициализация сервисов", в качестве которого systemd когда-то продали публике. За годы systemd стал отвечать за запуск, логи, сеть, DNS, домашние директории, шифрование, portable-сервисы, загрузку, контейнероподобные штуки, а теперь всё ближе подбирается к установке и управлению дисками.
IMDSD, Initramfs Management Daemon, выглядит как ещё один шаг в ту же сторону. Initramfs давно был местом, где у каждого дистрибутива свои скрипты, свои костыли, свои генераторы и вообще свой маленький уютный хаос. systemd предлагает сделать и этот слой более управляемым, предсказуемым и встроенным в общую модель.
storagectl туда же: управление хранилищами, блочными устройствами и всем, что лежит между железом и файловой системой. Не удивлюсь, если через пару лет обычный админ будет разбираться с дисками не через набор разрозненных утилит, а через очередную systemd-команду.
И вот тут начинается вечный холивар.
С одной стороны, systemd действительно решает реальную боль. Linux-инфраструктура исторически росла как набор отдельных инструментов, которые нужно склеивать руками, скриптами и молитвой. Для серверов, облаков, immutable-систем и автоматической установки единая модель управления выглядит логично. Особенно если хочется воспроизводимости: описал систему, получил систему.
С другой стороны, ощущение "systemd поглощает всё" никуда не делось. Просто потому что он и правда поглощает всё. Так уж получилось что недоделок в Linux-стеке всё же много, а systemd приходит туда с рабочим кодом, документацией и готовностью взять ответственность за ещё один неприятный слой.
Можно сколько угодно ворчать про монолитность и нарушение Unix-way, но реальность неприятнее: альтернативы часто либо фрагментированы, либо поддерживаются хуже, либо требуют от администратора слишком много ручной работы. systemd побеждает не потому, что всем нравится. Он побеждает потому, что закрывает скучные, но важные задачи.
Так что да, шутка про Systemd/Linux становится всё менее шуткой.
Сначала он запускал сервисы. Потом управлял логами, сетью, DNS и загрузкой. Теперь подбирается к установке ОС, initramfs и storage-слою.
Осталось дождаться systemd-kernel, systemd-bash и systemd-coffee.
Хотя ладно, последнее я бы, пожалуй, поставил.
Для ЛЛ: растет, цветет
Пока тут отдельные персонажи негодуют, что, покажись я ему со своим лавандовым рафом без кофеина, в комментариях на Минцифре, то есть Хабре, притом что Хабр уже пару лет модерируется минцифрой, и модераторов там, похоже, лишают премии, если кто-то из минцифры читает обидное), я пью чай, читаю всякое.
Во всяком (запрещенном в РФ) выпала новость:
AMD CEO Lisa Su recently demonstrated a compact AI PC powered by AMD’s Ryzen AI Max+ 395
Пошел читать.
Оказалось: Год назад, в 2025 году, AMD показали AMD Ryzen AI Max+ 395
Цитата
Китайский производитель ПК GMKtec, ранее остававшийся в тени, оказался в центре внимания после презентации мини-компьютера EVO-X2 с процессором AMD Ryzen AI Max+ 395. Анонс стал возможен благодаря прямому сотрудничеству с AMD: глава компании Лиза Су подписала первые экземпляры устройства.
Запуск новинки запланирован на май 2025 года, но уже сейчас модель позиционируется как «первый в мире настольный ПК с технологией Ryzen AI Max+», сочетающий флагманскую производительность с компактным форм-фактором.
https://www.ixbt.com/news/2025/03/23/amd-ryzen-ai-max-395-gm...
Тут можно посмотреть маркетинг – как AMD превосходит :
Apple M4 Pro vs. AMD Ryzen™ AI Halo1
NVIDIA DGX Spark vs. AMD Ryzen™ AI Halo2,3
Зимой 2026 был CES , где Лиза Су, генеральный директор АМД, выступала 2 часа -
Присоединяйтесь к выступлению председателя совета директоров и генерального директора AMD, доктора Лизы Су, на выставке CES 2026, самом масштабном технологическом событии в мире. Доктор Су возвращается на сцену CES в Лас-Вегасе, чтобы вместе с партнерами и клиентами рассказать о видении AMD в области создания решений для искусственного интеллекта будущего — от облачных вычислений до корпоративного сегмента, периферийных устройств и мобильных устройств.
На 21 минуте показали AMD Helios – стойка с ИИ от AMD . Внутри каждого модуля - чип с ладонь, Instinct MI455X , на 320 миллиардов транзисторов и 432 гигабайта памяти. Все это вкручено к AMD EPYC Venice (на 256 ядер Zen 6), сетевая часть от Pensando Systems. (их AMD купили в 2022 , кажется), на 800 гигабит (Pensando Vulcano 800G).
Тогда же показали (еще раз) AMD Ryzen AI Max, вроде в составе GMKtec EVO-X2.
Видео: 01:02:15 Announcing AMD Ryzen AI Halo
Стоит такое примерно 2000$, что где-то в 2-3 раза дешевле, чем крутить такую же ИИ нагрузку в облаке «за год».
19 мая 2026 в Шанхае прошел AMD AI Developer Day, где еще раз показали, какой AMD Ryzen хороший, приятный, итд.
И, кстати. Работает вся система под Windows 11 (под Linux тоже работает).
На этом все про AMD.
Неделю назад Microsoft выкатило текст и видео:
Microsoft SkillOpt Explained: How to Train AI Agent Skills (2026 Guide)
Стратегия управления для саморазвивающихся навыков агента. SkillOpt рассматривает компактный документ с навыками на естественном языке как обучаемое состояние замороженного языкового агента, а затем обучается работе с этим документом посредством поэтапного внедрения, рефлексии, ограниченного редактирования и отложенных проверок.
https://microsoft.github.io/SkillOpt/
https://flowtivity.ai/blog/microsoft-skillopt-train-ai-agent...
Я как-то упустил.
Что тут сказать? Прогресс идет. Оказывается, следующий AMD Advancing AI 2026, будет 22-23 июля 2026.
Литература
06.01.2026 AMD представила ИИ-ускорители Instinct MI430X, MI440X и MI455X и стоечную архитектуру Helios
https://3dnews.ru/1134874/amd-predstavila-iiuskoriteli-insti...
AMD AI DevDay 2026 — FAQ (, April 30, 2026)
AMD Advancing AI 2026
PS
Для всего остального есть Air LLM
AirLLM optimizes inference memory usage, allowing 70B large language models to run inference on a single 4GB GPU card without quantization, distillation and pruning. And you can run 405B Llama3.1 on 8GB vram now.
или вот такой чемодан:
На выставке Computex 2026 компания Nvidia анонсировала DGX Station для Windows — настольный суперкомпьютер на базе процессора Nvidia GB300 Grace Blackwell Ultra Desktop Superchip,
https://3dnews.ru/1142754/nvidia-predstavila-nastolniy-super...
Для ЛЛ: Системное администрирование – это про управление сервисом, а не только про ZverDVD и apt install
Трех китов – сети, сервера и системы хранения, я бегло рассмотрел, ссылок дал.
Остался четвертый кит, операционные системы.
Картина получается какая-то странная, потому что слоны стоят на черепахе, Великом А Туине, никак не наоборот. Черепахой будет назначен базовый набор сервисов – электричество, водопровод, теплоотведение, магистральные сети провайдеров, но про них ничего не говорится в этой саге. Потому что, с одной стороны, там такие же сети, только в кабеле не 12 жил, а 144, и не 10 метров кабеля, а 50 километров, и потом усилитель. И лазер там уже чуть-чуть мощнее. И главный враг – экскаватор и траншеекопатели. С другой – там не все так однозначно.
Дальше текст будет очень скомканным и спутанным, даже для меня. Не только потому, что текст писался в полночь, но и потому, что этот текст – попытка уложить мое текущее восприятие организационных структур и развития, в текст.
По трем основным операционным системам «для пользователей просто ПК», то есть Windows 11, Debian, и Ubuntu, и что там в импортозамещении сделали из Debian – астра, альт (не из Debian), роса, редос, написаны десятки учебников. В основном, учебники представляют собой справочники для заучивания вида «у ls есть ключи, у grep есть ключи, у Windows есть powershell», или «у виндовс есть сервисы, у линукс демоны", "для запуска вывода в текст нажмите влево вверх влево Y , esc q!" .
По системе для мак вы все и так знаете. Сначала мак, потом тыквенный латте на миндальном молоке, потом самокат, потом прямоток, домовина, домовина, погост, мужеложец.
Для пользовательского сегмента «на уровне вкатывания» ничего сузественно не меняется с момента смерти Novell NetWare. То есть: установили систему, настроили, как-то работает.
Кнопка пуск переехала, эка невидаль. Это вы интерфейс Windows server 2012 и тамошней кнопки пуск не видели. Особенно в терминале.
Драйвера еще можно поставить, и, как и 20, и 30 лет назад, поиграть в рулетку «драйвера для Linux».
Для Windows настроили WSUS (если есть), для Linux что там сейчас настраивают, apt update && apt upgrade ставят в крон, потому что вручную обновлять никто ничего не будет?
Вопреки многолетним историям (с 1995 года) слухи про смерть Windows for workgroups сильно преувеличены.

По состоянию на конец 2025-го суммарная доля всех версий Windows, установленных на десктопах и ноутбуках, составляла 66,47%. Для сравнения, годом ранее этот показатель достигал 73,38%. На втором месте по распространенности располагается OS X, доля которой в годовом исчислении сократилась с 14,16% до 7,75%. Замыкает тройку macOS с 4,71%. Еще 3,86% пришлось на различные платформы с ядром Linux против 4,13% годом ранее. На пятой позиции находится Chrome OS, у которой доля в годовом исчислении сократилась с 1,89% до 1,23%.
В исследовании отмечается, что для 15,98% персональных компьютеров тип операционной системы определить не удалось. В 2024 году доля неизвестных платформ составляла 6,43%.На российском рынке в сегменте ПК также доминируют различные варианты Windows с суммарной долей 81,87%. С macOS работают примерно 4% владельцев настольных компьютеров и ноутбуков, тогда как платформам на ядре Linux отдают предпочтение 3,35% пользователей
Вендекапец, конечно. Но, MS решил уйти с рынка Windows mobile, я уже и не вспомню почему.
С точки зрения работы, для пользовательского сегмента будут характерны следующие задачи:
- Установка любой ОС. С современным инсталлятором это сделает почти кто угодно после 1-2 кратного показа «жми сюда, потом сюда». WDS \ PXE сюда же.
- Настройка доступа к сети, сводящаяся к тому, что надо вбить 5 блоков по 4 цифры. IP, маску, шлюз, два DNS. Или даже и их не надо, DHCP работает, для ipv6 и DHCP не надо.
- Настройка сетевого доступа, сводящаяся к выводу ярлыка на рабочий стол и включения пользователя в группу (usermod -aG groupname username, или из GUI),
- Установка пакета программ, ключей шифрования и подписи, прочих мелочей.
- Прочих настроек всяких доступов по готовой инструкции, скорее всего написанной до вас (если вы только вкатываетесь).
Скучная работа, которую легко формализовать, и описать инструкцией. Работа легкая, оплата низкая, условия труда «в офисе с кофеечком», никаких особых требований.
То же самое, «доступная работа после короткого обучения» касается всей первой линии «вкатунов». Достаточно быть не совсем конченым, много спрашивать, много переспрашивать, ничего не сломать.
Проблема: из первой линии тяжело перескочить на вторую.
И не потому, что на второй линии задачи сложнее. Скорее, нет, но задачи второй линии заключаются не в поддержке первой. То есть, и в ней тоже, но вторая линия занимается*, поддержкой рабочей инфраструктуры и сервисов, а не решением проблем, которую не может решить первая линия.
* по моему мнению, и это местами может быть не так, или совсем не так. Деление «первая вторая линия» очень условно.
Стоит сказать, что «сейчас» в технологии управления «всем», то есть Agile, выделяется два направления:
Команда Поддержки (Run)
Команда Развития / Изменений (Change)
Пока все, что я пишу, относится скорее к поддержке, чем к развитию.
ITSM\ITIL тоже не совсем про это.
Сложно перескочить из Run в Change, нужно головой начинать думать самостоятельно, и много биться головой об стену. Потому что готовых решений в Change нет, что с нейросетью, что без.
Возвращаясь к теме, операционные системы
С точки зрения бизнеса, и это для многих становится открытием, вообще не имеет значения, какая операционная система используется и на рабочих местах, и в оборудовании, и вообще.
Значение имеет стоимость ОС (то есть, капитальные затраты, CAPEX), операционные затраты на поддержку этой системы в работоспособном состоянии (сумма операционных расходов, OPEX, включая зарплату специалистов по поддержке), предсказуемость затрат, и управление рисками (см. список литературы). И стоимость переучивания и миграции.
Именно поэтому Windows server с времён NT 3.5 и Windows с 3.11 по 11 использовались, и используются, повсеместно в мире. В том числе Embedded. В том числе в оборудовании.
В том числе в US NAVY (вышло не очень, но попробовали).
В то время как Microsoft продолжает трубить об успехе своей операционной системы NT по сравнению с системами на базе Unix, ВМС США пересматривают свое решение о том, стоит ли использовать NT в качестве основной операционной системы. Системный сбой на борту крейсера USS Yorktown в сентябре прошлого года временно парализовал его работу, из-за чего он застрял в порту на оставшуюся часть выходных.
Однако, «не важно» не означает, что завтра можно пойти и всем поставить Убунту для рабочих мест, KDE Plasma, и везде заменить S2D на Ceph. Прежде всего потому, что S2D работает вместе с виртуализацией, а CEPH работает вместо виртуализации, и то, в основном, как и положено с времен vi, CEPH может или все портить, или бибикать.

Заключение
В какой-то момент мне стало все равно, с какой, и под какой ОС работать. ОС на рабочем месте – это средство запуска приложения: браузера, игр, консоли, IDE. Значение имеют бизнес требования и бизнес задачи, а не ОС.
Значение имеет то, с чем ты работаешь, что ты предложишь бизнесу, почем и почему. И далеко не все требования бизнеса относятся даже к финансам. И я не говорю про требования закона и регуляторов, или требования по аудиту, а именно по ограничениям бизнес процессов.

Но на этапе вкатывания нужно спокойно относиться и к Windows, и к Debian, и к MacOS, и попробовать все из этого поставить (кроме macos), в этом поработать, выбрать «что удобно».
Читать первые 5 пунктов именно в таком порядке, по мере выхода книг.
Остальные читать в любом порядке.
1 «Мифический человеко-месяц, или Как создаются программные системы» (англ. The Mythical Man-Month: Essays on Software Engineering)
2 Deadline. Роман об управлении проектами
3 Проект Феникс. Роман о том как DEVOPS меняет бизнес к лучшему
4 Весь цикл «Рождение советской ПРО»: https://topwar.ru/user/Sperry/
Можно читать даже комментарии, где пишут, что автор ничего не понимает, либерал и вредитель.
Но, среди членов клуба зануд он считается опасным интеллектуалом.
5 Билл Гейтс. Бизнес со скоростью мысли
Литература для части 12
Таненбаум, Современные операционные системы.
ФОРМИРОВАНИЕ КОМАНД ПОДДЕРЖКИ ИЗМЕНЕНИЙ КАК НОВЫЙ ИНСТРУМЕНТ УПРАВЛЕНИЯ ПЕРСОНАЛОМ В ОРГАНИЗАЦИИ
Из режима change в run: как развивать продукт, когда он запущен
Risk Management Standard
Политика управления рисками Банка России
Шпаргалка по общению с СПО-сектантами
Про СПО сектантов, и что с этим делать. Вступление к пособию по карго-культам в ИТ
PS
Технические знания при вкатывании, разумеется, важны. Можно сказать, критически важны.
Но после вкатывания возникнет три вопроса:
Что происходит,
Почему так происходит, «как же они не понимают»
Куда катиться дальше, и каким путем.
Повторюсь. Ситуация, как я ее вижу, и ее ирония в том, что вся унаследованная в РФ массовая система образования, и продаваемая массовая система "вкатывания в ИТ" ориентирована на заучивание шаблонов 20-40 летней давности, а не на «обучение тому, что нужно на рынке».
И уж никак не тому, чтобы «учить учиться» или «учить самому оценивать рынок и ситуацию на нем».
Лозунг «ВУЗ учит учиться» есть, а за ним гнилые доски, и слово из 3 букв.
Западная учебная литература, в том числе в стиле «производственный роман» иногда показывает «куда, и как применять знания», в том числе «зачем и почему это так». Но в таком виде с 100% сахарного сиропа в смузи, так далеко от реалий, что читать невозможно.
Поэтому следующие посты в серии будут про рынок труда, как я его вижу. Будут, если опять не уйду играть в компьютерные игры, потому что днем в нашей местности крайне жарко, а ночью комары. Или не будут совсем, потому что я пишу, и понимаю что пишу "справочник по справочникам", то есть какую-то картотеку ссылок.


