Вышла новая модель VibeThinker-3B
Озвучена новая модель VibeThinker-3B (https://huggingface.co/WeiboAI/VibeThinker-3B), показывающая, что компактная версия с 3 млрд параметров способна достичь уровня флагманских LLM на задачах с проверяемой логикой (математика, код, STEM).
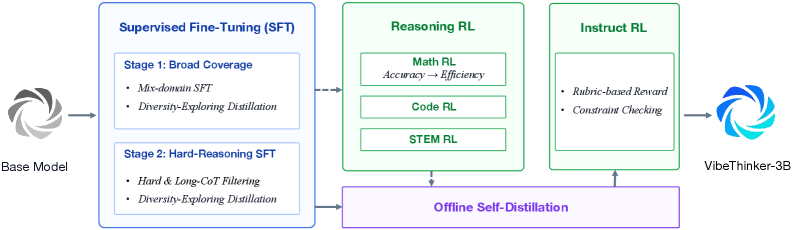
Пайплайн развивали от "Спектра" к "Сигналу", проходя через SFT и двухэтапное обучение по учебному плану, когда сначала шло широкое покрытие предметов, а затем фокус на трудных длинноцепочечных рассуждениях с финальной дистилляцией, которая сохраняла разнообразие решений. Дальнейший RL представлял собой мультидоменное (математика, код, STEM) обучение с алгоритмом MGPO, единым длинным контекстом (64K) и этапом "Long2Short" для повышения эффективности токенов без потери точности. Отбором и интеграцией лучших траекторий из разных доменов занималась офлайн-самодистилляция. Instruct RL настраивал строгое следование инструкциям без ущерба для рассуждений.
Гипотеза параметрического сжатия-покрытия утверждает, что способности моделей можно разделить на два типа. Способности первого типа, называемые параметрически плотными (верифицируемые рассуждения), могут быть "сжаты" в компактное ядро, не требуя гигантского объёма памяти. Способности второго типа, известные как параметрически экспансивные (открытые знания, общая эрудиция), нуждаются в широком покрытии фактов и длинном хвосте, что приводит к разрыву на GPQA-Diamond (70.2).
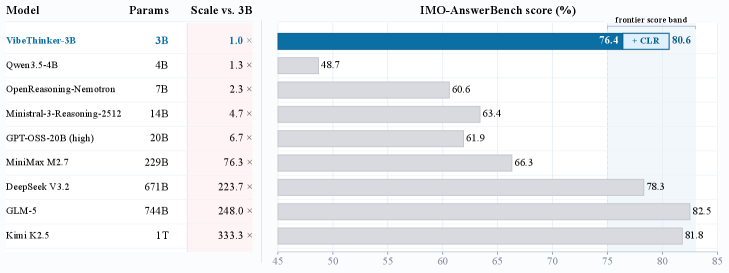
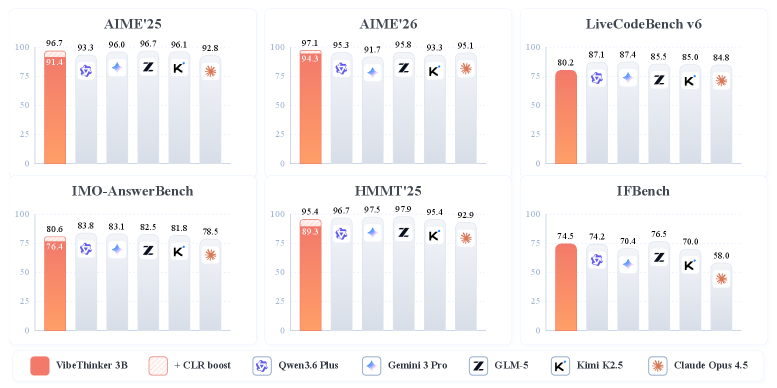
В результате её математические умения составляют 94.3 на AIME26 (97.1 с тест-тайм стратегией CLR), 89.3 (95.4) на HMMT25, 80.2 при Pass@1 на LiveCodeBench v6 и 76.4 (80.6) на IMO-AnswerBench, а принятые 96.1% на LeetCode (с апреля по май 2026 года) решения на новых соревнованиях сравнимы с GPT-5.2 и Gemini 3 Flash. На верифицируемых бенчмарках она сопоставима или превосходит модели масштаба DeepSeek V3.2 (671B), Kimi K2.5 (1T) и Gemini 3 Pro, при этом сохраняя инструкционную управляемость (IFEval 93.4).