Вышла новая модель для оцифровки изображений Unlimited OCR
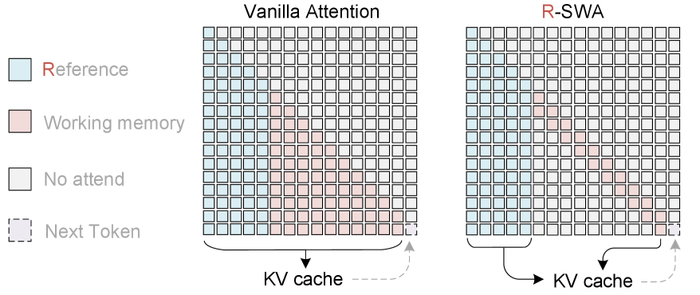
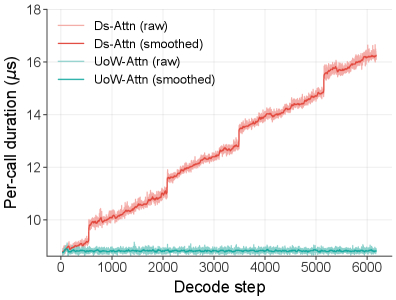
У одноэтапных OCR-моделей с LLM-декодером при длинных выводах линейно растёт KV-кеш, замедляя генерацию и увеличивая расход памяти, в отличие от человека.
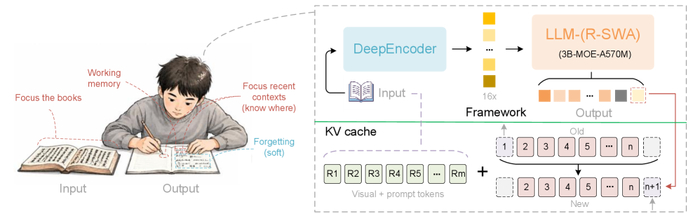
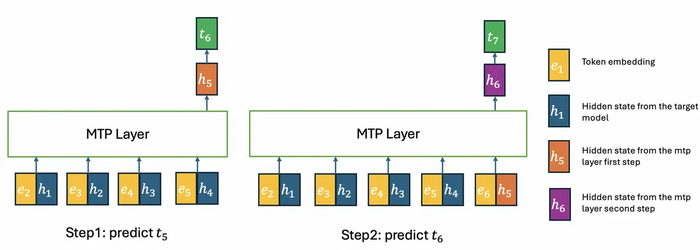
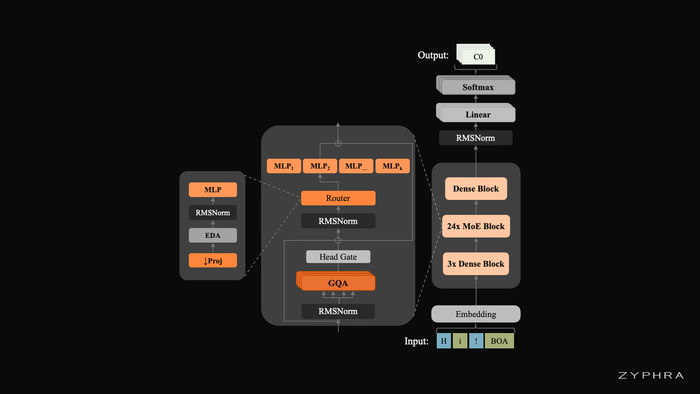
Unlimited OCR (https://huggingface.co/baidu/Unlimited-OCR) работает по-другому, заменяя все слои внимания декодера на предложенное референтное внимание со скользящим окном (R-SWA).
Базой выбрали DeepSeek OCR, включающий DeepEncoder с высокой компрессией и MoE-архитектуру с 3B параметров, из которых 0.5B активны.
Архитектура R-SWA даёт каждому токену видеть все референс-токены (визуальные и промт) и лишь последние n выходных токенов (по умолчанию 128), поэтому KV-кеш постоянен и визуальные признаки не "размываются", так как исключены из переходов состояний.
Сейчас истинно неограниченный парсинг упирается в длину входной обработки, хотя в будущем планируют удлинить контекст и встроить механизм динамической подгрузки этих данных. Притом R-SWA перспективно для ASR, перевода и других задач с длинным горизонтом.
В результате общая оценка набрала 93% на OmniDocBench v1.5 (+6% к базовому DeepSeek OCR). Была реализована возможность однопроходного парсинга десятков страниц документа при фиксированном KV-кеше и постоянной скорости декодирования, а при 6K токенов вывода скорость (TPS) на 35% выше, чем у DeepSeek OCR, за счёт устранения линейного роста затрат.