Вышла новая модель LFM2.5-Embedding-350M и LFM2.5-ColBERT-350M
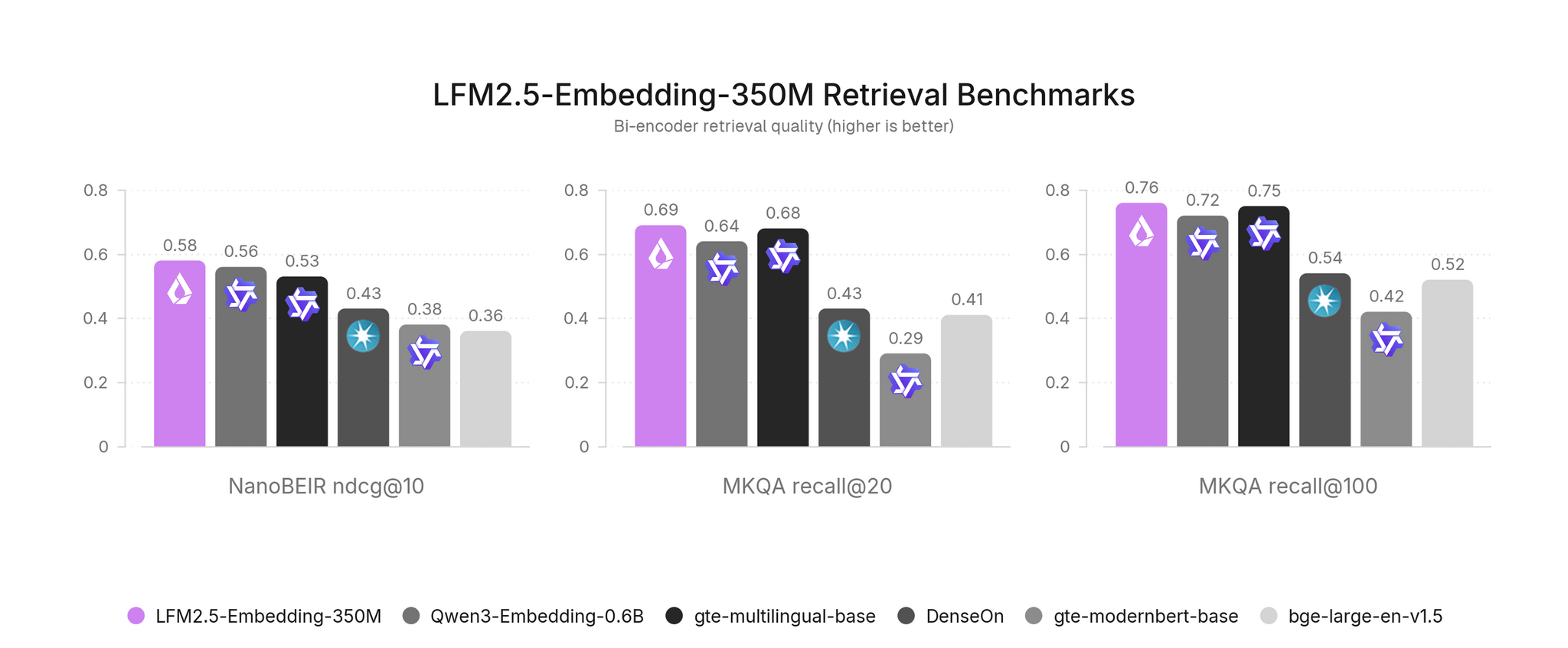
Запущены первые двунаправленные модели LFM2.5-Embedding-350M (https://huggingface.co/LiquidAI/LFM2.5-Embedding-350M) и LFM2.5-ColBERT-350M (https://huggingface.co/LiquidAI/LFM2.5-ColBERT-350M) от Liquid AI на основе LFM2.5-350M-Base, предназначенные для быстрого мультиязычного и кросс‑язычного поиска (11 языков) в коротких контекстах, таких как каталоги, FAQ и техподдержка.
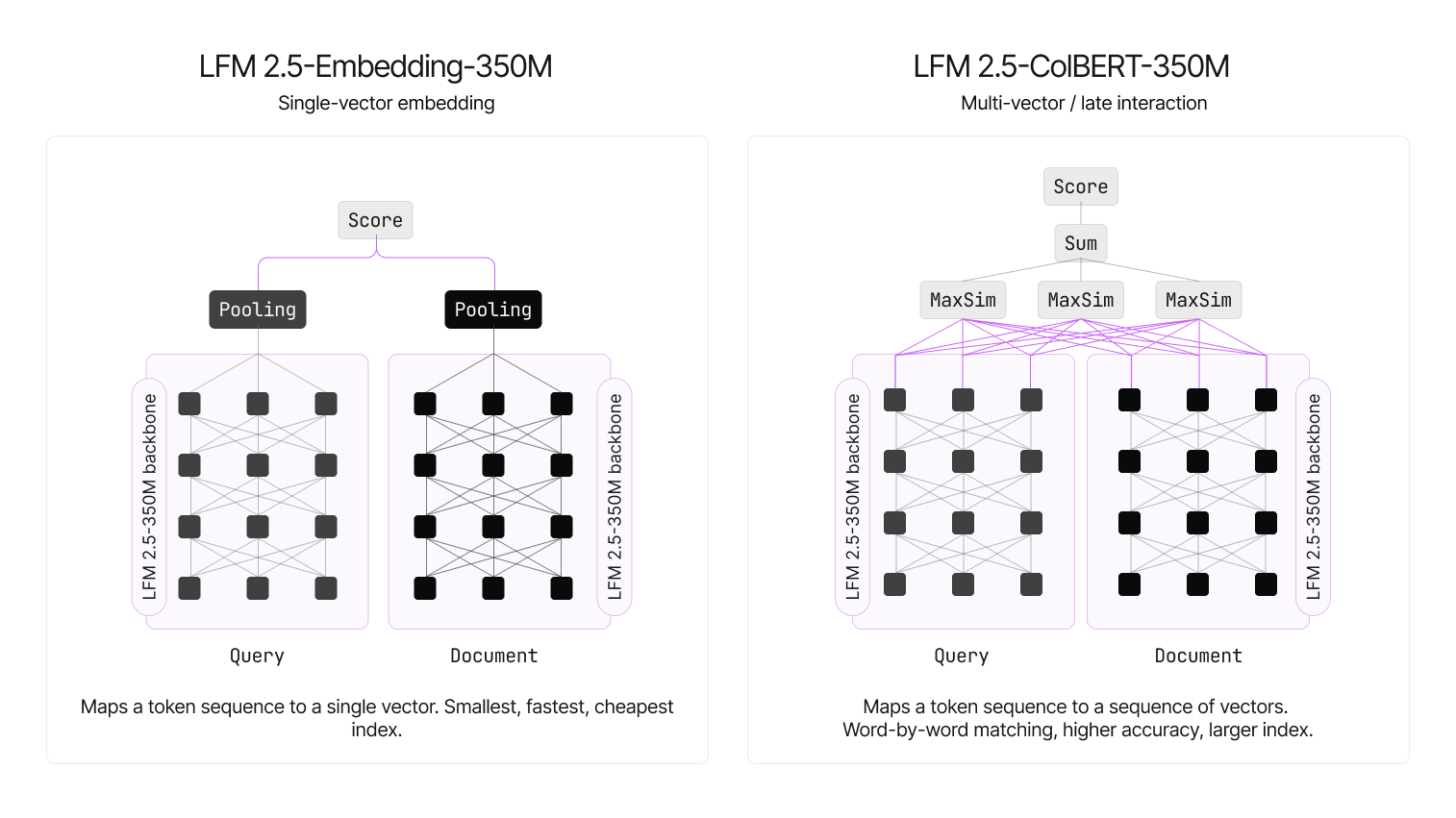
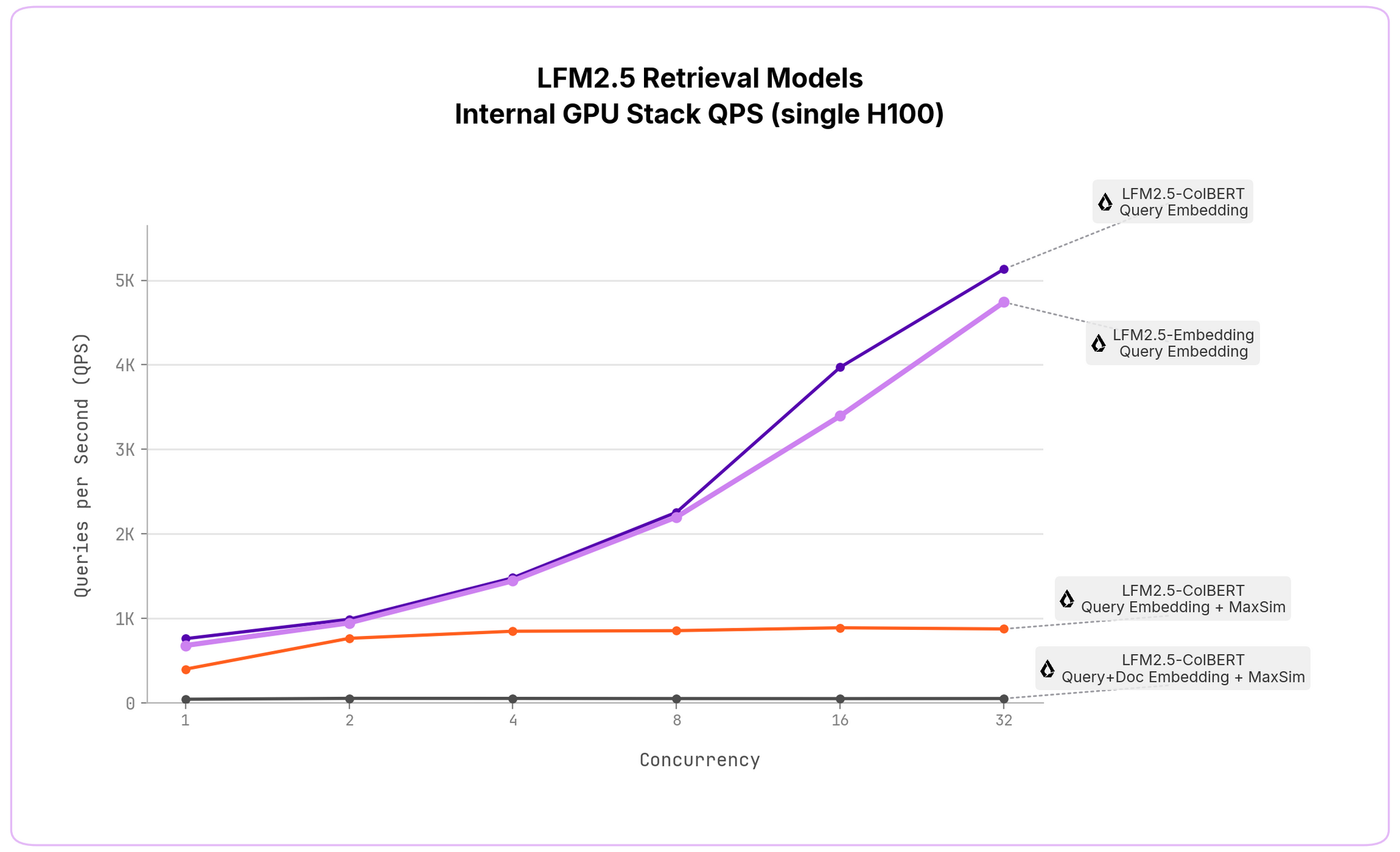
Версия Embedding создаёт один плотный вектор на документ, стремясь получить максимальную скорость при минимальном размере индекса, а версия ColBERT генерирует по одному вектору на токен, используя позднее взаимодействие (MaxSim) и обеспечивая повышенную способность к обобщению, хотя индекс становится больше.
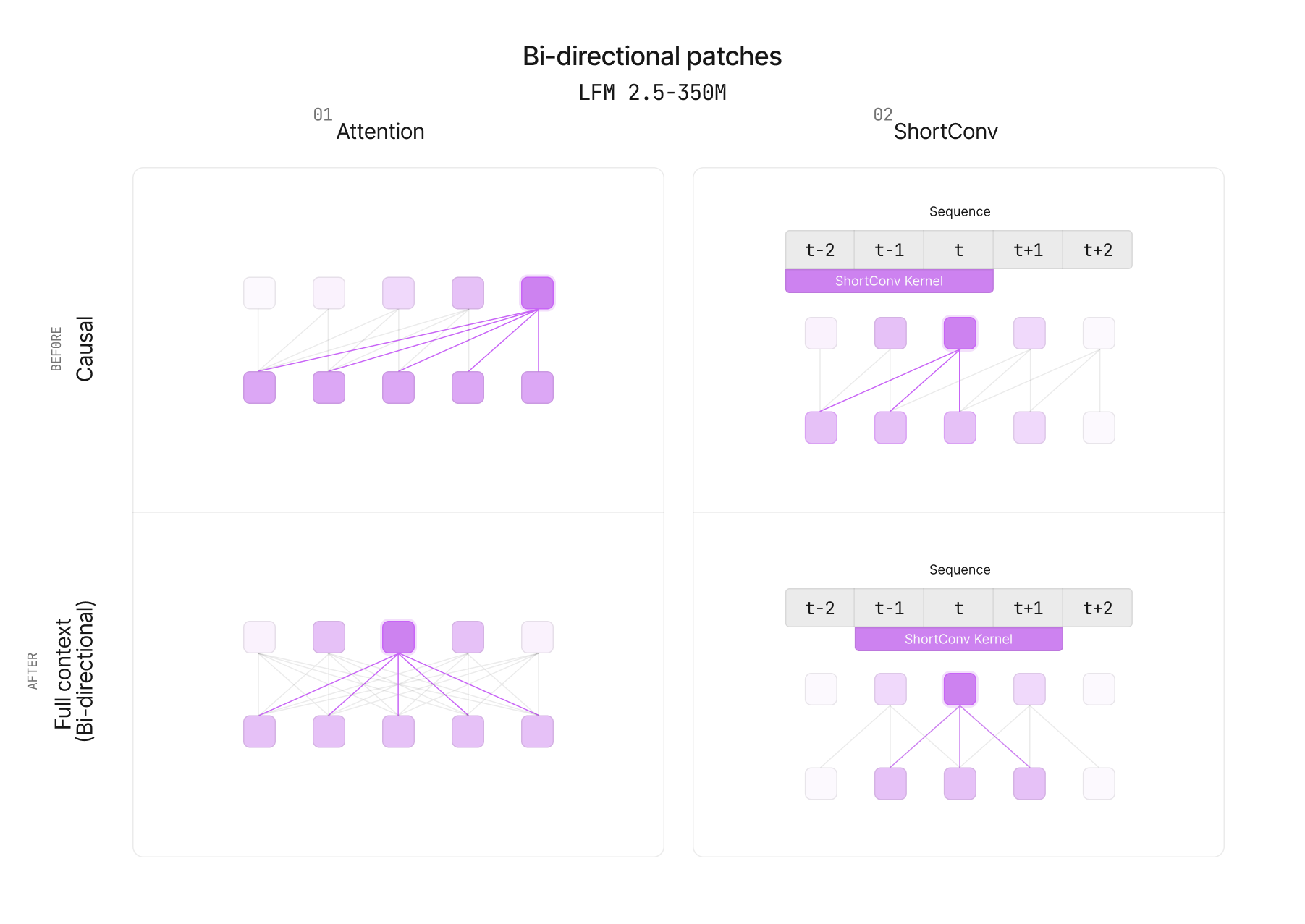
Архитектуру модифицировали, и каузальную маску заменили на двунаправленную, что позволило каждому токену видеть левый и правый контекст. Короткие свёртки LFM2 сделали некаузальными (симметричное локальное смешивание). Из общего двунаправленного энкодера достают либо CLS‑пулинг (Embedding), либо токенные эмбеддинги (ColBERT).
На первой стадии обучения проходило крупномасштабное сопоставительное предобучение на английском. Затем следовала стадия мультиязычной и кросс‑язычной дистилляции с сильного учителя (все 11 языков). Конечной стадией была тонкая настройка на сложных негативных примерах. Для всего процесса потребовались данные, извлечённые из курируемых внутренних и открытых английских датасетов, LLM‑перевод запросов и документов, чтобы расширить мультиязычность.
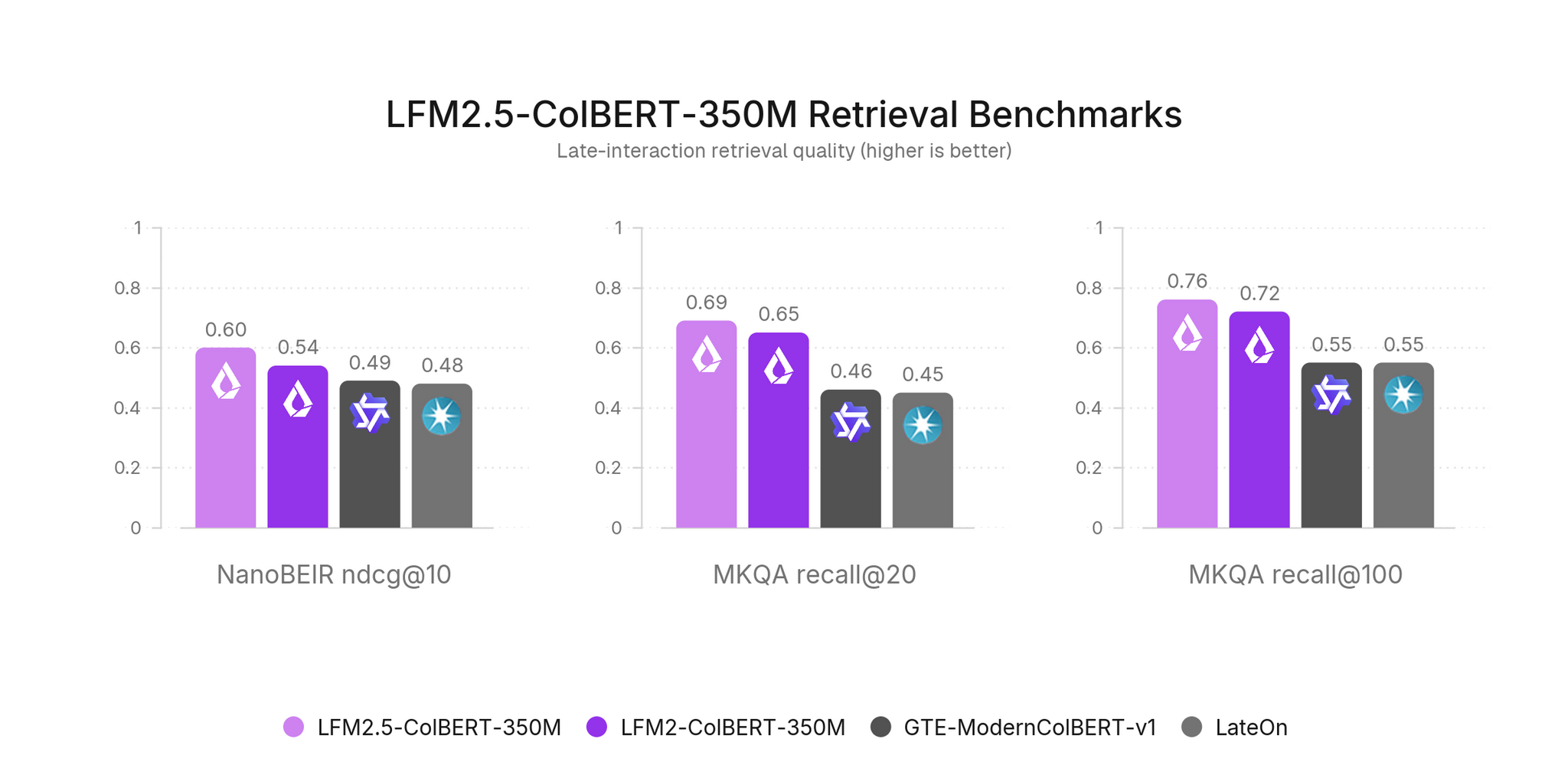
В результате обе модели имеют лучшие в классе показатели с 350M параметров по всем 11 языкам (арабский, немецкий, английский, испанский, французский, итальянский, японский, корейский, норвежский, португальский и шведский), пройдя мультиязычный поиск NanoBEIR, где NanoBEIR English признан подходящим заменителем для полного BEIR (корреляция, сдвиг около 15%), и кросс‑язычные ответы на вопросы MKQA‑11.