Устроившись на новое место, одной из первых задач я себе поставил проверку резервного копирования серверов своего окружения.
Формально бэкапы существовали. За них отвечала команда администрирования виртуальной инфраструктуры. Доступа к гипервизорам, их настройкам и самим резервным копиям у меня не было. Проверить консистентность я не мог, сколько займёт восстановление — не знал, и вообще не был уверен, что в случае аварии сервер реально поднимется. Поэтому для себя вывел простое правило: пока не проверил восстановление — бэкапа не существует.
Первый эксперимент
Из локальных средств резервного копирования нашлась интересная практика: раз в неделю снималась SquashFS-копия файловой системы и складывалась на NAS. С неё и начал.
После нескольких итераций получилось поднять сервер вручную: загрузка с Live-CD, разворачивание файловой системы, переустановка GRUB — и система стартовала уже с восстановленного диска.
Даже если такой способ когда-нибудь не позволит восстановить сервер целиком, остаются конфиги, сертификаты, служебные данные — то, что обычно в самый неподходящий момент приходится собирать заново. Уже одно это делает такой бэкап полезным.
Чёрный ящик
Схема бэкапа была простой: Puppet раскладывал скрипт резервного копирования на сервер, cron запускал его по расписанию. На этом контроль заканчивался. Есть ли свежий бэкап? Не пустой ли он? Можно ли на него рассчитывать? Ответа на эти вопросы не было.
Написал небольшую утилиту проверки. Она подключается к хранилищу, ищёт резервные копии каждого сервера и прогоняет простые проверки:
существует ли текущий бэкап;
существует ли предыдущий;
не слишком ли маленький получившийся архив;
не отличается ли его размер от предыдущего больше допустимого порога.
Это не гарантирует целостность данных, но ловит большинство типичных ошибок. А они нашлись! На удивление, полностью исправных серверов оказалось меньше, чем ожидалось. Где-то cron запускал скрипт с неправильным окружением. Где-то не хватало прав доступа. На части серверов отсутствовали нужные пакеты. Встречались и банальные ошибки в настройках. После исправления резервное копирование стало заметно стабильнее.
Новая проблема
Исправив одну проблему, бонусом получил следующую. Все серверы запускали бэкап в одно и то же время. Десятки машин одновременно начинали сжимать данные и лить их на сетевое хранилище. Канал забивался, скорость падала, часть копий завершалась с ошибками.
Разводить время запуска вручную под каждый сервер — не вариант, это не масштабируется и рано или поздно снова сломается при добавлении новых машин. Вместо этого решил изменить сам подход.
Оркестратор
Появился отдельный сервер-оркестратор. На каждом клиентском сервере создаётся специальный пользователь, которому разрешено выполнять ровно один заранее определённый скрипт резервного копирования с повышенными привилегиями — и ничего больше. Оркестратор хранит список серверов, последовательно подключается к каждому по SSH и запускает бэкап. Пока один сервер не закончит, следующий не стартует.
Привязки к конкретным машинам нет. Через Puppet любому серверу можно назначить роль клиента резервного копирования, роль оркестратора или обе сразу. Пользователи, права, ключи, скрипты, расписание — всё поднимается автоматически. Благодаря этому оркестратор можно перенести на другую машину без ручной перенастройки инфраструктуры.
В результате конкуренция за сетевой канал исчезла, да и нагрузка на хранилище стала более равномерной.
Скрипт бэкапа
Заодно доработал сам скрипт резервного копирования. Теперь он:
автоматически удаляет собственные копии старше четырёх недель, не трогая данные других серверов;
проверяет размер созданного архива и сравнивает его с предыдущим;
кроме самого архива рядом сохраняется информация, необходимая для восстановления сервера;
по завершении пишет небольшой файл состояния — дата выполнения, размер копии, итоговый статус, диагностическое сообщение.
Zabbix просто читает из файла состояние последнего бэкапа и сигнализирует, если копия давно не обновлялась, завершилась с ошибкой или подозрительно похудела.
Итог
Резервное копирование стало отдельной системой, которая сама разворачивается через Puppet, следит за своим состоянием, проверяет результат, сообщает о проблемах в мониторинг и позволяет восстановить сервер даже при полной потере виртуальной машины.
Теперь легко отследить, в каком состоянии находится резервное копирование. Существующий процесс стал более управляемым, а уровень тревожности стал ниже.
Если считаете что я изобрёл велосипед, или есть советы как сделать бэкапирование более качественным, то пишите в комментариях, с удовольствием почерпну для себя ценную информацию!
Привет, пикабушники. На связи Евгений Сивков. Обычно я пишу про налоги, бухгалтерский учет, выпускаю книги и веду семинары для профессиональной аудитории. Но сегодня тема другая, хотя и бьет прямо по кошельку.
Пока мы с вами разбираем очередные изменения в законодательстве и сдаем отчетность, хакеры устроили настоящую охоту на бухгалтеров. И они очень хорошо подготовились.
Один клик — минус 3 миллиона. Как хакеры в 2026 году охотятся на бухгалтеров
Цифры сухие, но отрезвляющие. Только за первое полугодие 2026 года на бухгалтерские отделы совершено 13 тысяч кибератак. Это больше, чем за весь прошлый год. Средний ущерб от одного такого взлома — 3 миллиона рублей.
Хакеры больше не хотят взламывать обычных пользователей, чтобы украсть чью-то пенсию или аккаунт в соцсети. Им нужны компании. А ключи от денежного сейфа компании, доступы к Клиент-Банку и электронному документообороту — у главбуха.
Забудьте про старые вирусы, которые просто перехватывали пароли. Сейчас в ходу троян DarkWatchman. Это не просто шпион, это пульт дистанционного управления вашим компьютером. Он тихо сидит в системе, записывает каждое нажатие клавиш и делает одну гениальную вещь: в момент, когда бухгалтер формирует платежку или зарплатный реестр, троян незаметно подменяет реквизиты. Деньги уходят не контрагенту, а на подставные счета. И самое противное — он рассылает себя дальше по вашей базе клиентов и поставщиков.
Как это выглядит на практике? Никаких писем про выигрыш в лотерею или срочные проблемы с картой. Вам падает письмо от знакомого поставщика. Тема: «Акт сверки» или «Счет на оплату». Письмо может прийти даже через ЭДО. Файл называется, например,Счет.pdf, но иконка нарисована так, что выглядит как документ. А по факту это исполняемый файл.
Отдельный вид искусства — фейковые сайты. Ищете в поиске «скачать КриптоПро», попадаете на сайт-клон, который визуально неотличим от оригинала. Скачиваете «утилиту для ЭЦП», устанавливаете, а вместе с ней ставите троян.
Как не попасться. Тут нужно включить здоровую паранойю
Первое. Смотрите на адрес отправителя, а не на красивое имя в поле «От». Мошенники используют омоглифы — символы, которые выглядят как буквы. Вместо латинской «o» стоит цифра «0», вместо «l» — единица. Адрес nashp0stavschik.ru — это не ваш поставщик.
Второе. Расширение файла. Если видите двойное имя вроде Уведомление.pdf.exe — это вирус. Точка.
Третье. Золотое правило. Пришел счет с новыми реквизитами или странными условиями? Не ленитесь, возьмите телефон и позвоните контрагенту. Живым голосом. Пять минут разговора спасут вам три миллиона.
А теперь самое важное. Что делать, если вы уже нажали на файл и поняли, что что-то не так? Компьютер начал тормозить, курсор двигаться сам по себе или появились странные файлы.
Главная ошибка, которую совершают 90 процентов людей: они в панике выключают компьютер. Не делайте этого. Вы уничтожите следы, и айтишники не смогут понять, что именно украли и как глубоко залезли хакеры.
Правильный алгоритм: мгновенно отключите интернет. Выдерните сетевой кабель или отключите Wi-Fi. Это разорвет связь трояна с сервером хакеров. И сразу бегите к системному администратору. Скрывать проблему бессмысленно и опасно.
Коллеги, бдительность — это не просто красивое слово из инструкций по охране труда. Это финансовая безопасность вашего бизнеса. Работайте с банком на отдельном компьютере, не используйте его для серфинга в интернете, ставьте обновления Windows и требуйте от руководства нормальный корпоративный VPN.
Перешлите этот текст своим бухгалтерам, финансовым директорам и собственникам бизнеса. Пусть читают.
А вы сталкивались с фишинговыми атаками на почту? Как вычисляете мошенников? Делитесь в комментариях.
Half-Life 3, регулярно фигурирующая в файлах Valve под кодовым именем HLX, продолжает находиться в активной разработке. Несмотря на прогнозы инсайдеров о возможном анонсе в 2025 году, официальных новостей не последовало.
По словам Тайлера Маквикера, Valve намеренно откладывает презентацию: компания крайне требовательна к качеству и не хочет повторять ошибки прошлых лет, выпуская «сырой» продукт. Проект дорабатывается до идеала, чтобы соответствовать статусу легендарной франшизы.
Косвенные признаки прогресса подтверждаются регулярными находками датамайнеров в движке Source 2. В файлах Dota 2, Counter-Strike 2 и Deadlock энтузиасты постоянно обнаруживают новые технологии: продвинутую физику объектов, разрушаемость окружения, современные системы частиц и улучшенное сглаживание. Изначально ходили слухи о привязке игры к «железу» Valve, но теперь, судя по всему, проект стал кроссплатформенным. Сейчас студия хранит полное молчание, предпочитая качественный результат спешке ради хайпа.
Как часто вам приходилось судорожно доставать ноутбук в метро или в дороге просто для того, чтобы чекнуть упавший DNS, заглянуть в логи атакованного SSH-сервера или быстро прикинуть маску подсети? Обычные мобильные SSH-клиенты хороши, но иногда хочется иметь под рукой готовый набор быстрых сетевых утилит, завёрнутых в привычную гиковскую эстетику терминала.
Поэтому я решил написать CyberBuddy Console — карманный симулятор консоли и швейцарский нож для админов, разработчиков и энтузиастов ИБ. Писал на React Native + Expo, ориентируясь на скорость, автономность и консольный UX.
Что умеет этот карманный терминал уже сейчас?
Инспекция сети: Полноценный пинг (ping), замер скорости (speedtest) и сканирование локалки на активные хосты (scan).
Разбор полётов (DNS & WHOIS): Быстрый nslookup (A, MX, NS записи) и вытягивание инфы по доменам.
Веб-инспектор: Аналог curl для проверки HTTP-заголовков и защитных щитов сайтов.
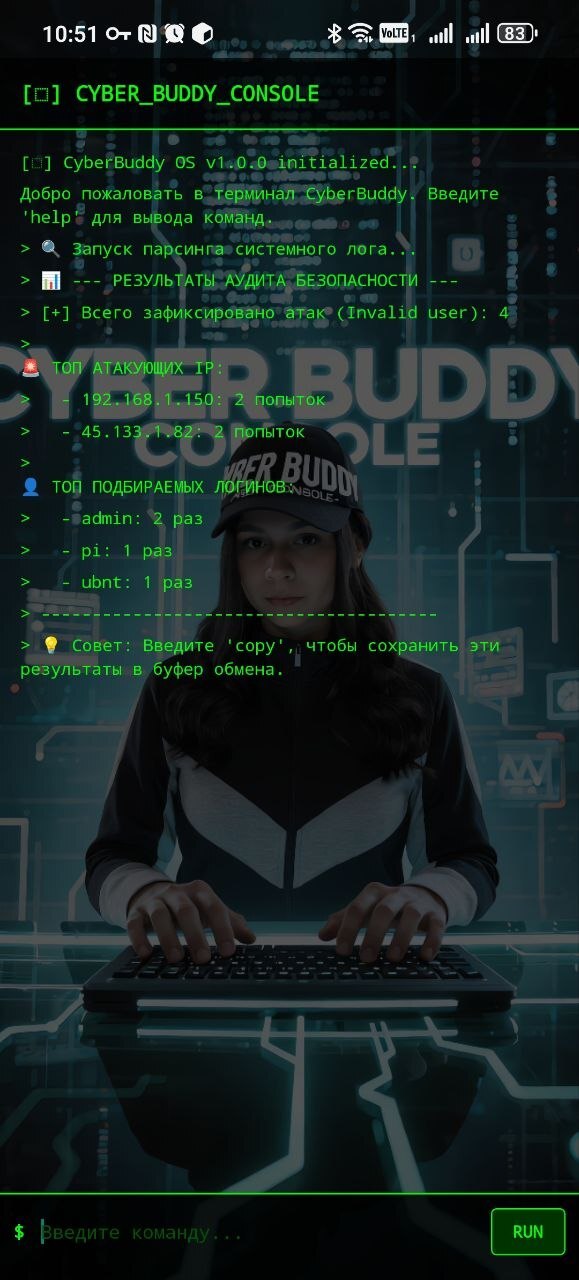
Аудит логов (моя гордость): Команда parse умеет на лету обрабатывать сырые логи SSH-сервера (auth.log), агрегировать данные и выводить детальный отчёт по TOP-атакующим IP, подбирающим пароли.
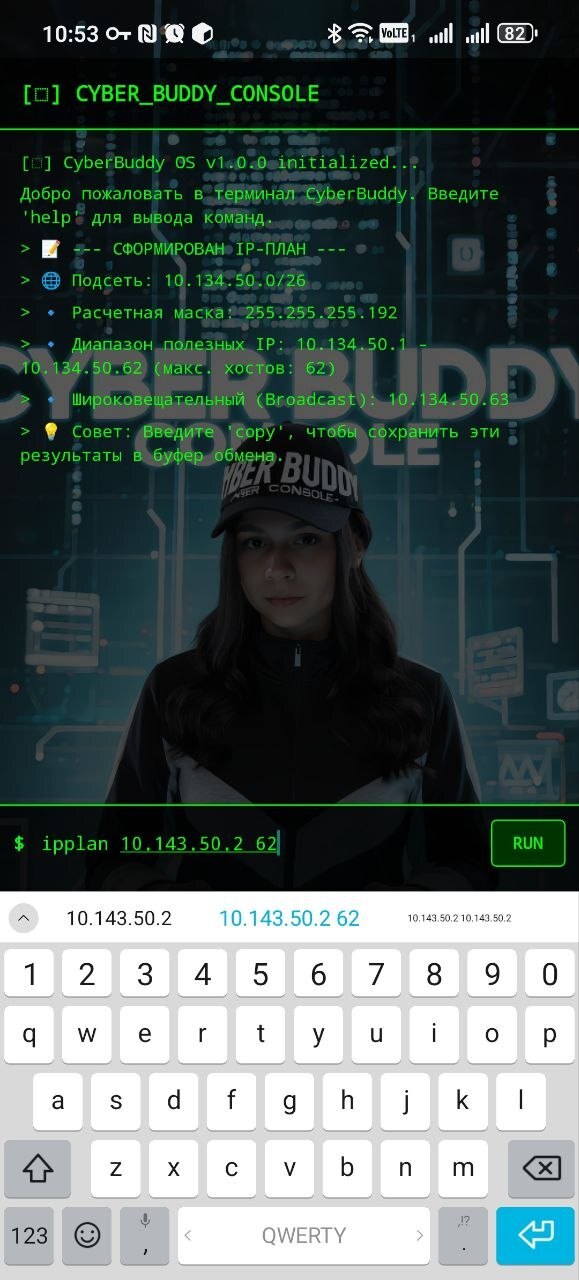
Калькулятор подсетей: Команда ipplan для быстрого расчёта масок и диапазонов адресов.
Валидация на ходу: Встроенный синтаксический анализатор valid для JSON и Linux CRON-выражений.
Немного фана: Логическая мини-игра по брутфорсу зашифрованных кодов доступа, чтобы размять мозги.
Проект полностью бесплатный, без рекламы и скрытых трекеров. Исходный код я открыл, так как в сфере ИБ доверие к софту — превыше всего.
Буду рад конструктивной критике, идеям для новых команд и реквестам!
Ссылка на GitHub (там же лежит готовый APK в релизах):
Если вам неудержимо хочется использовать оборудование из музея для современной разработки — статья специально для вас.
Машины должны служить а не требовать ресурсы. И автор патча l9 об этом знает.
Эпический баг
Сейчас наверное некоторые читатели сильно удивятся:
с 2007 года в ядре Linux живет серьезный баг, приводящий к полному зависанию системы при работе под большой нагрузкой на память.
На дворе на момент написания статьи май 2025 года, так что баг успел отпраздновать совершеннолетие и открыть первую бутылку пива.
Оригинальный репорт выглядит так:
Разумеется разработчики ядра в курсе проблемы, но по ряду причин.. не считают этот баг важным.
Да, вы правильно прочитали:
«полное зависание системы под нагрузкой» и «разработчики не считают важным исправлять» — как вам такие реалии Linux?
Более того, недавно тикет с описанием этого бага вообще закрыли с эпической формулировкой «just become obsolete»:
С легким намеком, что некоторым стоит перестать собирать себе компьютеры по помойкам:
but now I don't bother with less than 32Gb of RAM for a desktop.
Теперь прокрутите обсуждение бага в трекере вниз и посмотрите на последнее сообщение о проблеме:
Специально сохранил картинкой для истории, вдруг не поверите.
Оно конечно все замечательно и у самого автора этой статьи давно 64Гб на одной из рабочих машин, а некоторые коллеги успели впихнуть даже 128Гб, причем в ноутбук — чтобы мы наконец увидели SUSE Linux, которая не тормозит.
Но к сожалению одними любителями компьютерного антиквариата данная проблема не ограничивается — на нынешние облачные времена типичное рабочее окружение Linux это виртуальная машина, с ограниченным обьемом памяти. Скорее всего даже ваш корпоративный сайт крутится на виртуальной машине с 4Гб памяти.
Так что на самом деле проблема касается практически всех пользователей Linux, а не только идейных нищебродов энтузиастов, собирающих себе оборудование по музеям.
Как так получилось
Если вы хоть немного понимаете в компьютерах, прочитав абзац выше и сопоставив масштаб проблемы и отношение к ней разработчиков Linux, думаю уже сделали определенные выводы:
либо команда разработки ядра Linux — поголовно некомпетентны, либо у автора контракт с рептилоидами в описании выше был упущен ряд важных нюансов.
Правда как обычно где‑то между — «особенных» среди современных разработчиков Linux действительно хватает, но ряд нюансов я все же намеренно упустил.
Опишу в какой момент проявляется этот баг:
надо долго и упорно увеличивать нагрузку на использование памяти, причем маленькими порциями и обязательно из нескольких разных процессов — чтобы OOM Killer не успел отработать.
На практике надо либо заниматься тренировкой нейросетей, либо непрерывно гонять тяжелые приложения на Java/Node (в первую очередь IDE) и постоянно запускать сборку больших проектов.
И все это на неподготовленном офисном оборудовании с 4-6 Гб памяти, представляющем историческую ценность, либо в виртуальной машине.
Патч l9ec
Уже давно существует неофициальный патч, решающий описанную проблему с зависанием квадратно-гнездовым радикальным способом:
The kernel does not provide a way to protect the working set under memory pressure. A certain amount of anonymous and clean file pages is required by the userspace for normal operation. First of all, the userspace needs a cache of shared libraries and executable binaries. If the amount of the clean file pages falls below a certain level, then thrashing and even livelock can take place.
По сути этим патчем формируется небольшой объем памяти (тот самый working set), которую запрещается перегружать даже самым хитрым приложениям, откусывающим память по килобайтам.
Разумеется патч заметили и тут находится архив эпической переписки в рассылке Linux Kernel длиною в год, где автор патча пытается объяснить окружающим что он не верблюд и проблема действительно есть.
Однако патч в мейнстрим так и не попал, что наводит на определенные нехорошие мысли.
История с Xanmod
Помимо основной версии ядра т. н. «vanilla», исходники которого выкладываются на широко известном kernel.org, существуют «васянские сборки» — наборы патчей ядра, собранные энтузиастами под конкретную задачу.
Одна из таких сборок называется Xanmod и посвящена работе современного ядра на desktop-системе с минимальными визуальными задержками:
XanMod is a general-purpose Linux kernel distribution with custom settings and new features. Built to provide a stable, smooth and solid system experience.
Так вот на момент появления l9ec патча, он был включен в сборку Xanmod:
Но в последних 6.х версиях Xanmod его уже нет, на что есть формальная причина — появление вот этого патча, вроде как окончательно решающего проблему c зависанием:
На данный момент MGLRU в mainline и скорее всего работает прямо сейчас и у вас в системе, если конечно у вас современный линукс и MGLRU не отключен вручную.
К сожалению принцип работы MGLRU другой (см. комментарий выше про 32Гб памяти на десктопе) и тестировался его функционал тоже в другом месте:
On Android, our most advanced simulation that generates memory pressure from realistic user behavior shows 18% fewer low-memory kills, which in turn reduces cold starts by 16%.
Как нетрудно догадаться, «realistic user behavior» на мобильном Android несколько отличается от тотальной перегрузки тяжелыми средствами разработки на дохлом десктопе или еще более слабой виртуальной машине.
Поэтому «продвинутым пользователям Linux» в очередной раз придется заботиться о себе и своих проблемах самостоятельно.
Эта история — еще одна причина, по которой стоит использовать *BSD. Реклама.
Портирование на 6.х ядро
К сожалению автор патча l9 видимо устав бодаться с идиотами, не стал переносить свой замечательный патч в 6.х ветку ядра, решив что раз более умные ребята из Google выкатили MGLRU — от его решения толку больше не будет.
Как ни странно, но это не так и l9 патч куда более предсказуем и надежен как удар ломом, в отличие от цирка с аж 14 патчами MGLRU:
These initial multi-generational LRU patches amount to 14 patches at the moment and in a patched kernel can be enabled via the LRU_GEN Kconfig switch
Собственно эта статья появилась на свет после того как автор опять словил зависание под нагрузкой во время работы над большим проектом, из-за чего и решил откопать дедовский пулемет портировать известный патч в 6.х ядро.
За основу был взят последний патч для 5.х ветки без учета MGLRU: le9ec-5.15.patch а его логика добавлялась в Xanmod-версию ядра 6.14.5.
Ниже по шагам объясняю как выполнить перенос логики патча, чтобы процедуру можно было повторить и на более новых ядрах и на «vanilla» версиях.
Скачиваем архив с Xanmod ядром и l9-патч по ссылкам выше и распаковываем.
Стоит сразу предупредить, что размер текущей версии ядра Linux в распакованном виде ~1.8 Гигабайт, а для сборки понадобится еще ~28 Гигабайт.
Вот такие нынче ядра.
Разумеется применить готовый diff автоматически для ветки 6.х не получится, так что будем переносить логику патча по шагам.
Всего в рамках патча изменения происходят в пяти файлах:
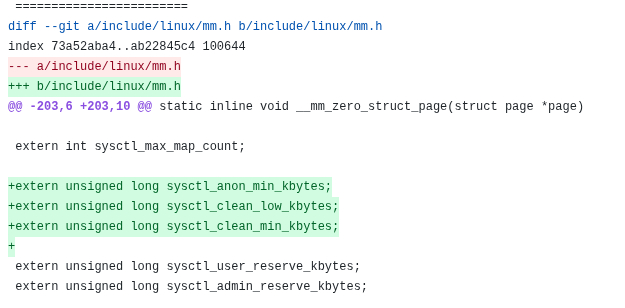
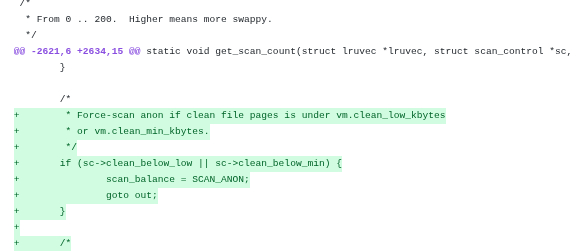
Поскольку исправлять документацию нам не очень актуально, первый файл можно пропустить. Таким образом первое актуальное исправление находится в файле include/linux/mm.h, куда добавляются глобальные переменные, отвечающие за настраиваемые лимиты:
Все что нужно сделать — вставить строки в файл include/linux/mm.h:
/* * Force-scan anon if clean file pages is under vm.clean_low_kbytes * or vm.clean_min_kbytes. */ if (sc->clean_below_low || sc->clean_below_min) { scan_balance = SCAN_ANON; goto out; }
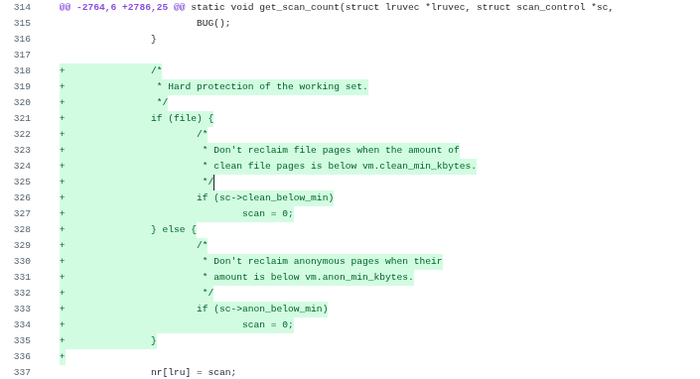
Следующая правка в этом же файле должна быть вставлена в этот же метод get_scan_count, но ниже по коду — ориентируйтесь на строку nr[lru] = scan;благо она такая одна:
Я вставил логику проверки сразу над ней:
/* * Hard protection of the working set. */ if (file) { /* * Don't reclaim file pages when the amount of * clean file pages is below vm.clean_min_kbytes. */ if (sc->clean_below_min) scan = 0; } else { /* * Don't reclaim anonymous pages when their * amount is below vm.anon_min_kbytes. */ if (sc->anon_below_min) scan = 0; } nr[lru] = scan;
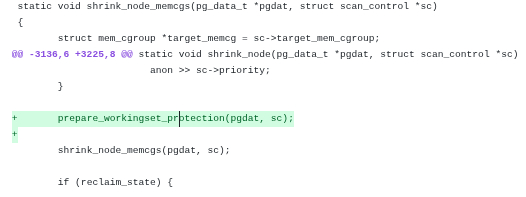
Следующей правкой добавляется новая функция prepare_workingset_protection, которая должна вызываться из существующего метода shrink_node_memcgs:
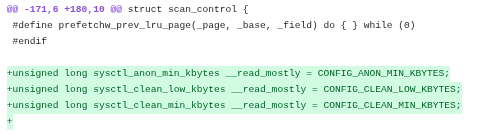
Так что вам надо найти функцию shrink_node_memcgs (она такая одна) и вставить новую функцию prepare_workingset_protection над ней:
static void prepare_workingset_protection(pg_data_t*pgdat, struct scan_control *sc) { /* * Check the number of anonymous pages to protect them from * reclaiming if their amount is below the specified. */ if (sysctl_anon_min_kbytes) { unsignedlong reclaimable_anon;
/* * Check the number of clean file pages to protect them from * reclaiming if their amount is below the specified. */ if (sysctl_clean_low_kbytes || sysctl_clean_min_kbytes) { unsignedlong reclaimable_file, dirty, clean;
reclaimable_file = node_page_state(pgdat, NR_ACTIVE_FILE) + node_page_state(pgdat, NR_INACTIVE_FILE) + node_page_state(pgdat, NR_ISOLATED_FILE); dirty = node_page_state(pgdat, NR_FILE_DIRTY); /* * node_page_state() sum can go out of sync since * all the values are not read at once. */ if (likely(reclaimable_file > dirty)) clean = (reclaimable_file - dirty) << (PAGE_SHIFT - 10); else clean = 0;
Собственно последняя правка это вызов новой функции из существующей shrink_node_memcgs:
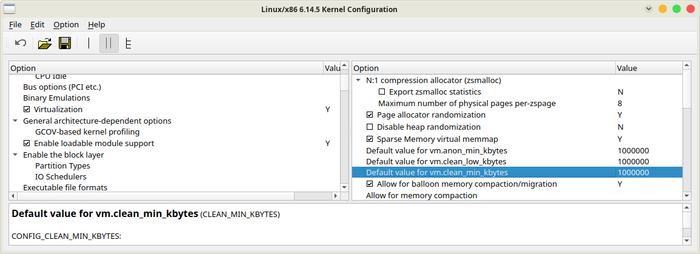
После внесения всех этих исправлений, запускаем один из вариантов настройки ядра:
make xconfig
И наблюдаем новые поля настройки:
Цепочка сборки и установки ядра совершенно стандартная:
make && make modules && make modules_install && make install
К сожалению это еще не все и прежде чем патч заработает надо будет отключить MGLRU, который как я уже описывал — успели внести в основную ветку ядра:
cat /sys/kernel/mm/lru_gen/enabled
Должен показать 0x0007 если MGLRU включен, отключить можно командой:
echo 0 | sudo tee /sys/kernel/mm/lru_gen/enabled
Вот тут у автора патча лежат готовые скрипты для автоматизации всего этого цирка. Я же просто добавил строчку с отключением в /etc/rc.local.
Пруфы
Для тестов портированного патча, был взят один из моих боевых ноутбуков Lenovo Z580 2012го года выпуска, с 8Гб памяти:
На нем постоянно творится всевозможная дичь — тут пять разных операционных систем и куча проектов и инструментов для разработки на каждой.
Поэтому без особого труда были одновременно запущены:
PostgreSQL с реальной базой
MySQL тоже с реальной базой
Intellij Idea
VSCode
Сборка проекта на Node.js с Webpack и hot reload
Сборка достаточно крупного Java-проекта (~3000 исходных файлов)
Chromium с 20 вкладками
Напоминаю что все это на 8Гб реальной памяти и на ноутбукe. Причем в качестве ОС в этот раз была обычная Ubuntu:
Как-то так это выглядит в действии:
Через неделю после публикации я решил пойти еще дальше и поставил пропатченное с l9 ядро на ноутбук 2007 года с 3Гб памяти. И повторил тесты с нагрузкой. Видео тут.
Все более чем работает и пропатченное ядро замечательно отрабатывает свою пайку.
Эпилог
Можно сколько угодно стебаться с пожеланиями «купи себе наконец нормальный компьютер», скажу что намеренно и давно использую старое железо — в первую очередь для оценки производительности создаваемого ПО.
И это одна из причин, по которой у нас получаются технические чудеса вроде Телепорты.
Если вы пока не дошли до столь глубокой стадии просвещения в разработке — все равно стоит знать, что мы ловили подобные зависания и в виртуальных машинах с Linux, например на CI‑сервере при сборке нескольких проектов одновременно.
Так что актуальность описанного все же высокая и как получилось, что столь простой и очевидный патч, который гарантированно решает проблему до сих пор не используют активно — ума не приложу. Ну и разумеется автору патча лучи респекта, благо это лучший представитель отечественной инженерной школы.
Статья была опубликована на Хабре, оригинал, в котором автор статьи себя не сдерживал и в красках рассказал все что думает о разработчиках ядра Linux как обычно можно найти в нашем блоге.
ИИ против репетитора по программированию: кто выиграл за 30 дней (спойлер: всё неоднозначно)
Представь: нашёл репетитора по Python. Хороший, с опытом в продакшне, объясняет понятно. 3 500 рублей в час, два раза в неделю. Параллельно попробовал ИИ-ментор на . И запустил эксперимент на месяц: что даст каждый?
Вот что вышло.
Неделя 1: репетитор ведёт с разгромным счётом
Первое занятие с репетитором — разбор почему твой код работает, но написан плохо. Репетитор смотрит на функцию в 40 строк и говорит: «Это можно сделать в три». Показывает как. Объясняет list comprehension так, что наконец понимаешь зачем оно вообще нужно.
ИИ-ментор в первую неделю — так себе. Задаёшь вопросы слишком широко, получаешь ответы слишком широко. «Объясни мне Python» — бесполезно. Учишься формулировать точнее.
Счёт после недели 1: репетитор 1 — ИИ 0
Неделя 2: ИИ начинает отыгрываться
Между занятиями с репетитором — пять дней. В эти пять дней застрял на рекурсии. Не понимаешь почему стек вызовов работает именно так.
Репетитор недоступен. Открываешь ИИ-ментор, пишешь: «Объясни мне стек вызовов при рекурсии на примере факториала, пошагово». Получаешь разбор с трассировкой каждого вызова. Переспрашиваешь три раза — ИИ объясняет три раза, без раздражения.
На следующем занятии репетитор спрашивает как разобрался — и удивляется что разобрался сам.
Счёт после недели 2: репетитор 1 — ИИ 1
Неделя 3: неожиданный поворот
Репетитор даёт задачу: реализовать бинарное дерево поиска с операциями insert, search, delete. Две недели назад это звучало бы как заклинание. Сейчас садишься, думаешь, пишешь.
Застрял на delete — удаление узла с двумя потомками. Репетитор на следующем занятии объяснил за 15 минут лучше, чем любая статья.
ИИ-ментор в эту неделю — ежедневные вопросы по теории графов. «Чем BFS отличается от DFS на практике, когда что использовать?» — конкретный ответ с примерами задач. Экзаминатор на той же платформе создал тест по деревьям за минуту — выяснилось что балансировку понимаешь плохо. Лучше узнать сейчас, чем на собеседовании.
Счёт после недели 3: ничья, но оба молодцы
Неделя 4: итог
30 дней, 8 занятий с репетитором, 28 000 рублей... нет, стоп. 8 занятий × 3 500 = 28 000 рублей за месяц. Очень много!
Что дал репетитор: понимание что такое «нормальный код», разбор сложных структур данных с живым объяснением, задачи точно под уровень.
Что дал ИИ-ментор: ответы в любое время суток, объяснение концепций столько раз сколько нужно, тесты для проверки понимания, скорость покрытия теоретических вопросов.
Кто выиграл?
Никто. Или оба — зависит как смотреть.
Репетитор незаменим когда нужен разбор кода живым взглядом и задачи под контролем. ИИ незаменим в промежутках — когда репетитор спит, а вопрос не ждёт.
Если бы пришлось выбирать только одно: на раннем этапе — ИИ дешевле и доступнее. На финальном этапе перед собеседованием — репетитор эффективнее.
Всем привет! Хочу поделиться забавным опытом с одним известным хостинг-провайдером. Спойлер: смех сквозь слезы.
Краткая предыстория:
Решил взять промо-тариф у Aeza с хранилищем NVMe. Первое время все летало, сайт работал быстро, команды выполнялись моментально. Думаю, красота.
А потом что-то пошло не так. Сервер начал тормозить. Команды и обновления пакетов выполняются с задержкой, сайт еле дышит. Думаю: "Может, я что-то напортачил?" Начал проверять.
И тут началось веселье.
Запускаю тесты и вижу:
Задержки чтения (clat): 64 мс
Утилизация диска в тесте: 94%
Для тех, кто в теме: это классические показатели HDD, а не NVMe. Ну, думаю, бывает. Написал в поддержку.
Поддержка: "Да, у вас на промо-тарифе ограничение 1000 IOPS."
Я такой: "Ок, 1000 IOPS это не быстро, но 64 мс задержки? Даже с ограничением 1000 IOPS у нормального хранилища задержки: 1-5 мс."
Поддержка: "Мы пересадим вас на другой хост, чтобы соседи не мешали."
Я: "О, круто, спасибо!"
Дальше мой любимый момент.
Пересадили. Запускаю тесты снова:
Задержки чтения: 64 мс (да, те же самые)
Утилизация: 94,81% (даже чуть выше)
🤡
Ну, думаю, может, они не поняли? Пишу еще раз. Привожу цифры до и после, спрашиваю: "Почему у меня задержки как у HDD, если вы продаете NVMe?"
Ответ поддержки (цитирую):
"Со стороны сервера критических отклонений не выявлено... для виртуальной машины установлены ограничения... 1000 IOPS... сервер функционирует в штатном режиме, признаков неисправности или деградации работы не наблюдается."
То есть они официально подтвердили, что 64 мс задержки и 1000 IOPS, это их штатная норма для промо-тарифа с "NVMe".
Краткий вывод:
Вы покупаете тариф с пометкой NVMe, а получаете HDD с программным зажимом до 1000 IOPS и задержками 64 мс. И поддержка говорит, что это норма.
Я не знаю, как у них с физикой, но у меня по физике NVMe выдает десятки тысяч IOPS и задержки 0,1-1 мс. А 1000 IOPS и 64 мс чисто про механический диск с бензопилой.
Мораль истории:
Если берете у Aeza промо-тариф с пометкой "NVMe" знайте, что это "NVMe" в кавычках.
P.S. Хотите вернуть себе веру в человечество? Вот буквально цитата из их ответа, которая меня добила:
"сервер функционирует в штатном режиме... признаков деградации не наблюдается"
Да, 64 мс задержки не деградация. Это просто эволюция в обратную сторону.
P.S. Если у вас есть промо-тариф Aeza, то запустите тест. И напишите в комментариях, что у вас. Интересно, я один такой счастливый обладатель "NVMe по-русски" или нас много?
AUR (репозиторий у арчеров) недавно словил массовую атаку: неизвестные скомпрометировали больше тысячи заброшенных пакетов и попытались протащить вирус через npm-зависимости.
В десятки пакетов добавили код, чтобы при каждом открытии терминала вылезало сообщение:
вы еблан и юзаете говно kal дистрибутив поставьте нормальный дистр и не позорьтесь... скажите спасибо, что я ещё вам вирусни не добавил, а чисто напоминалку в консоли сделал. happy pride month! use Nocord, RAC and coproxy by mr sugoma! новый албанский вирус из россии скачать
(что такое Nocord, RAC и coproxy оставляю тебе для факультативного изучения, почитаешь на сайберпедии)
Дальше западные юзеры понесли это в переводчики — и понеслось. kal машинно превратился в Kali Linux, поэтому часть людей решила, что атака направлена именно на Kali. А «албанский вирус» восприняли буквально и начали обсуждать новую страшную киберугрозу из Албании 😨
Периодически обозреваю разные обсёры ИБ у себя в канале: