


Нейросеть рисует и пишет
38 постов
38 постов

16 постов

116 постов

40 постов
273 поста

114 постов

21 пост
Оригинал на основном техническом блоге : Марковская цепь для DBA: эволюция, фильтрация и путь в промышленную эксплуатацию (возможны исправления и дополнения)
Версия 12.1 — важный эволюционный шаг, однако её точность, устойчивость и пригодность для реальных систем ещё предстоит доказать через серию масштабных исследований: от долгосрочной валидации и борьбы с дрейфом распределения до интеграции в мониторинговый ландшафт и обеспечения надёжности в нештатных ситуациях.
Эволюция прогнозной модели: жёсткость, динамика, селективность.
Прогнозирование аварийных ситуаций в сложных динамических системах, таких как СУБД PostgreSQL, сталкивается с фундаментальной проблемой нестационарности распределения наблюдаемых параметров и множественностью сценариев развития инцидентов.
В настоящей работе представлена эволюция марковской модели прогнозирования, прошедшей путь от статичной поглощающей матрицы с жёстко заданными критериями аварийности (версия 10.1.6) до самонастраивающегося итеративного механизма с динамически обновляемым перечнем критических состояний на основе эмпирического риска (версия 11.3), и, наконец, до текущей версии 12.1, где ключевым нововведением стала фильтрация переходов при оценке стабильности — исключение критических состояний и редких событий с числом переходов менее порогового значения.
Данная эволюция отражает постепенное осознание того, что надёжность прогноза определяется не только точностью вероятностных оценок, но и устойчивостью самой модели к выбросам и разреженным данным.
В статье последовательно анализируются архитектурные изменения, сравниваются подходы к определению аварийности, расчёту горизонтов и параметров забывания, а также формулируется комплекс открытых проблем, требующих решения для перехода к промышленной эксплуатации.
Первая реализация опиралась на предположение о стационарности и использовала фиксированные аварийные критерии. Модель работала с 189 состояниями, которые представляли собой комбинации трёх параметров — корреляции, тренда ОС и тренда ожиданий. Аварийным считалось только одно строгое условие: отрицательная корреляция при падающем тренде ОС и растущем тренде ожиданий.
Прогноз строился через поглощающую матрицу, пересчитываемую при каждом обновлении вероятностей. Горизонты были фиксированными — 1, 15, 30 и 60 минут. Достоверность оценивалась по пятибалльной шкале на основе объёма данных и стабильности вероятностей. Это было рабочее решение, но оно не учитывало, что реальные инциденты могут проявляться иначе, а параметры системы со временем меняются.
Методология заложеная в версия 11 принципиально отличается. Вместо жёсткого условия разработчики ввели таблицу critical_states, которая автоматически пополняется функцией refresh_critical_states на основе эмпирического риска из таблицы инцидентов. Теперь аварийные состояния определяются не раз и навсегда, а извлекаются из истории наблюдений.
Одновременно изменился сам механизм прогноза: поглощающая матрица уступила место итеративному расчёту с обнулением вероятностей критических состояний на каждом шаге. Горизонт стал единым и задаётся в конфигурации (по умолчанию 30 минут). Появились новые отчёты, в том числе mchain_quality_report, а достоверность стала штрафоваться за нестабильность.
Это был шаг к самообучающейся системе, но оставалась проблема: стабильность модели оценивалась по всем переходам, включая редкие и аварийные, что могло искажать реальную картину.
Последний релиз не вносит кардинальных архитектурных изменений, но существенно уточняет, как мы измеряем стабильность.
Главное нововведение — фильтрация при расчёте максимального изменения вероятностей переходов (max_prob_change).
Из анализа исключаются:
переходы в критические состояния (те, что перечислены в critical_states);
состояния, для которых за анализируемый период зафиксировано менее 200 переходов.
Это позволяет отсечь шум: редкие события и аварийные пики перестают влиять на оценку стабильности, делая её более репрезентативной. Кроме того, скорректированы параметры забывания по умолчанию — интервал уменьшен с 180 до 60 минут, а базовый коэффициент альфа — с 0.1 до 0.07. Такая настройка обеспечивает более плавную адаптацию к новым данным, снижая резкие скачки.
Фильтрация внедрена во все ключевые функции: mchain_check_sufficiency, mchain_forecast_reliability, mchain_reliability_report, evaluate_forgetting_params и report_stability_trend. Теперь каждый отчёт о надёжности учитывает только статистически значимые и некритические переходы.
Если обобщить различия, можно выделить несколько осей развития.
По определению аварийности:
Версия 10: жёсткое логическое условие, зашитое в код.
Версии 11 и 12: динамический список critical_states, обновляемый по данным инцидентов.
По механизму прогноза:
Версия 10: поглощающая матрица, перестраиваемая при каждом обновлении.
Версии 11 и 12: итеративное обнуление вероятностей критических состояний без использования поглощающей матрицы.
По горизонту прогноза:
Версия 10: четыре фиксированных горизонта (1, 15, 30, 60 минут).
Версии 11 и 12: единый горизонт, задаваемый в конфигурации (по умолчанию 30 минут).
По расчёту стабильности:
Версии 10 и 11: учитывались все переходы без исключений.
Версия 12: исключены переходы в критические состояния и состояния с числом переходов менее 200.
По параметрам забывания по умолчанию:
Версии 10 и 11: interval_minute=180, base_alpha=0.1.
Версия 12: interval_minute=60, base_alpha=0.07.
Версия 12.1 — не революция, а эволюционное уточнение, которое делает модель более устойчивой к выбросам и редким событиям.
Благодаря фильтрации оценка стабильности стала объективнее, а прогнозы — достовернее в реальных условиях эксплуатации.
Однако пока рано говорить о промышленном внедрении инструмента: требуется много дополнительных исследований и тестирования для реализации методики на продуктивной нагрузке.
Среди ключевых направлений, нуждающихся в проработке, можно выделить следующие.
Валидация на длительных исторических данных. Текущие эксперименты проводились на ограниченных выборках. Для подтверждения устойчивости модели необходимо протестировать её на многомесячных архивах производительности PostgreSQL с разнообразными паттернами нагрузки: сезонными пиками, миграциями данных, обновлениями версий СУБД и изменениями конфигурации. Только такая валидация позволит оценить, насколько модель сохраняет точность при смене эксплуатационных условий.
Адаптация к нестационарности. Производительность реальных систем со временем меняется — растут объёмы данных, эволюционируют запросы, обновляется аппаратное обеспечение. Цепь Маркова первого порядка, предполагающая стационарность переходных вероятностей, может давать сбои в таких условиях. Необходимы исследования того, как часто нужно переобучать модель, какие механизмы обнаружения дрейфа распределения следует внедрить и как автоматически перестраивать пространство состояний при изменении характера нагрузки.
Проблема разреженности данных. В версии 12.1 уже введён порог в 200 переходов для включения состояния в расчёт стабильности. Однако на продуктивных системах многие состояния могут оставаться редкими, особенно в начальный период наблюдения. Это ставит вопрос о разработке методов сглаживания (например, байесовской априорной регуляризации) или агрегации схожих состояний, чтобы повысить статистическую значимость оценок без потери чувствительности к аномалиям.
Вычислительная масштабируемость. При росте числа наблюдаемых параметров пространство состояний может быстро разрастаться. В текущей реализации используется 189 состояний — комбинация трёх параметров. На продуктивной системе может потребоваться учёт дополнительных метрик (количество активных сессий, размер буферного кэша, интенсивность контрольных точек и т.д.), что приведёт к экспоненциальному росту числа состояний. Требуется исследование методов сокращения размерности и эффективных структур данных для хранения и обновления матрицы переходов в реальном времени.
Калибровка гиперпараметров. В версии 12.1 скорректированы параметры забывания: interval_minute уменьшен с 180 до 60, а base_alpha — с 0.1 до 0.07. Однако оптимальные значения этих параметров могут существенно зависеть от конкретной рабочей нагрузки: для высокодинамичных систем требуется более быстрое забывание, для стабильных — напротив, более долгая память. Необходимы систематические исследования по автоматическому подбору гиперпараметров, возможно, с использованием методов оптимизации, адаптивных к текущим условиям.
Оценка качества прогнозов на продуктивной нагрузке. В лабораторных условиях модель показывает обнадёживающие результаты. Однако на реальных системах цена ложноположительных и ложноотрицательных срабатываний совершенно иная. Ложное предупреждение может отвлечь администратора от действительно важных задач, а пропуск инцидента — привести к простою. Необходима разработка метрик качества, учитывающих асимметрию потерь, а также калибровка порогов срабатывания под конкретные SLA и бизнес-приоритеты.
Интеграция с существующими системами мониторинга. Промышленное внедрение требует бесшовной интеграции с распространёнными стеками наблюдения (Prometheus, Zabbix, Grafana и др.). Это означает не только техническую совместимость по протоколам и форматам данных, но и согласование моделей данных: метрики, используемые цепью Маркова, должны соответствовать тем, что уже собираются в продуктивной среде, без необходимости доработки агентов сбора.
Интерпретируемость для инженеров. Цепи Маркова дают вероятностный прогноз, но администраторам баз данных нужны не только цифры, но и понятные объяснения: почему модель ожидает инцидент, какие именно переходы между состояниями привели к такому выводу, на какие метрики следует обратить внимание в первую очередь. Требуются дополнительные исследования в области объяснимого искусственного интеллекта (XAI) применительно к марковским моделям.
Сравнительные исследования с альтернативными подходами. На сегодняшний день не проведено систематического сравнения марковского подхода с другими методами прогнозирования — рекуррентными нейронными сетями, градиентным бустингом на временных рядах, скрытыми марковскими моделями или байесовскими структурными временными рядами. Без такого бенчмарка на репрезентативных датасетах сложно утверждать, что цепь Маркова является оптимальным выбором, а не просто удобной и интерпретируемой альтернативой.
Тестирование на отказоустойчивость. В продуктивной среде модель должна корректно работать при сбоях в сборе данных, временной недоступности хранилища метрик, скачках задержек и других аномалиях инфраструктурного уровня. Необходимы стресс-тесты, моделирующие различные сценарии деградации самого механизма прогнозирования, чтобы гарантировать, что отказ модели не усугубит ситуацию в системе.
Таким образом, путь к промышленному внедрению лежит через серию масштабных исследовательских и инженерных работ: от валидации на больших данных до интеграции в существующий мониторинговый ландшафт и обеспечения надёжности в нештатных ситуациях.
Проект открыт для сотрудничества, и каждый из этих вызовов может стать отдельной темой для совместной разработки.
Проведённый анализ трёх версий марковского прогностического инструмента демонстрирует последовательное улучшение его репрезентативности и робастности за счёт отказа от статичных допущений, внедрения эмпирически обновляемого списка критических состояний и, в особенности, введения фильтрации статистически незначимых и аварийных переходов при оценке стабильности. Скорректированные параметры забывания (интервал 60 минут, базовый коэффициент 0.07) обеспечивают более плавную адаптацию к текущей нагрузке, снижая ложную волатильность прогнозов.
Вместе с тем, как показано в работе, достигнутые результаты носят предварительный характер и не могут считаться достаточными для промышленного внедрения без проведения обширных исследований по следующим направлениям: валидация на многолетних архивах производительности с учётом сезонных и структурных изменений; разработка методов обнаружения дрейфа распределения и автоматического переобучения; решение проблемы разреженности данных через байесовскую регуляризацию или агрегацию состояний; обеспечение вычислительной масштабируемости при росте размерности пространства; калибровка гиперпараметров, адаптивная к типу нагрузки; построение асимметричных метрик качества прогнозов с учётом стоимости ошибок; интеграция с существующими стеками мониторинга; повышение интерпретируемости для инженерного персонала; сравнительный бенчмаркинг с альтернативными методами машинного обучения; а также стресс-тестирование отказоустойчивости самого предиктора.
Каждый из перечисленных вызовов представляет собой самостоятельную исследовательскую задачу, и их последовательное решение определит дорожную карту дальнейшего развития проекта, исходные коды которого открыты для академического и индустриального сотрудничества.
Взято с основного технического канала Postgres DBA (Возможны исправления в исходной статье).
Все функции (mchain_predict_risk_1min, mchain_predict_risk_k, обёртки для 15, 30, 60 минут) возвращают набор из четырёх полей:
risk (REAL)
Вероятность аварии (попадания в аварийное состояние) на заданном горизонте. Значение от 0.0 до 1.0.
curr_situation (TEXT)
Код ситуации, объясняющий, как был получен риск. Возможные значения:
'unknown_state'
'no_risk'
'risk_calculated'
curr_transitions_to_risk (INT)
Количество прямых переходов из текущего состояния в любое аварийное состояние, зафиксированных в обученной матрице вероятностей.
curr_total_transitions_known (INT)
Общее число различных целевых состояний, в которые можно перейти из текущего состояния (согласно модели).
Числовой смысл
risk – это оценка условной вероятности того, что за указанное количество минут (1, 15, 30, 60) система хотя бы один раз окажется в аварийном состоянии.
Для mchain_predict_risk_1min – вероятность перехода на следующей минуте.
Для mchain_predict_risk_k – вероятность хотя бы одного попадания в аварию за k шагов (минут), вычисленная через поглощающую цепь Маркова.
Диапазон значений
0.0 – согласно модели, авария невозможна (нет переходов в аварийные состояния).
0.05 – используется как априорная вероятность в случае, когда текущее состояние модели неизвестно (ситуация unknown_state).
>0.0 – модель оценивает ненулевой риск.
Практическая интерпретация (уровни риска)
< 0.01 (<1%) – риск крайне низкий, система стабильна.
0.01 – 0.10 (1%–10%) – умеренный риск, рекомендуется мониторинг.
0.10 – 0.30 (10%–30%) – значительный риск, желательно принять превентивные меры.
> 0.30 (>30%) – высокий риск, требуется немедленное вмешательство.
Важно: Прогнозы зависят от обученной модели и могут быть недостоверны, если модель имеет низкий рейтинг достоверности (см. раздел 6).
Поле даёт контекст вычисления риска и помогает диагностировать, почему модель выдала то или иное значение.
Когда возникает
Текущие метрики производительности (current_correlation, os_trend, wait_trend) отсутствуют (например, таблица cluster_stat_median пуста).
Или текущее состояние не найдено в справочнике state_descriptions (практически невозможно, если заполнены все 189 комбинаций).
Или в таблице markov_probabilities нет записей для данного состояния (состояние ни разу не встречалось в обучении).
Что означает
Модель не знает, как ведёт себя система из данного состояния. Возвращается априорная вероятность 0.05 (1–(0.95)^k для многошагового прогноза). Прогноз недостоверен.
Что делать
Дождаться, пока через mchain_train_step накопятся переходы из этого состояния. Если состояние появляется часто, но модель его не узнаёт – проверить, вызывается ли fill_state_descriptions() и не сброшены ли таблицы частот.
Когда возникает
Текущее состояние известно, но в матрице вероятностей markov_probabilities нет ни одного перехода из него в аварийные состояния. То есть curr_transitions_to_risk = 0.
Что означает
Согласно накопленным данным (с учётом забывания), из текущего состояния никогда не было прямого перехода в аварию. risk возвращается как 0.0 (даже для многошагового прогноза, потому что поглощающая матрица при отсутствии исходных переходов даст нулевую вероятность).
Степень уверенности
Высокая, но только если модель достаточно обучена (рейтинг достоверности ≥3). При малом объёме данных может быть ложным (авария возможна, но ещё не встречалась).
Когда возникает
Текущее состояние известно, и в модели есть хотя бы один переход из него в аварийное состояние (curr_transitions_to_risk > 0). Риск вычислен на основе вероятностей из markov_probabilities (для 1 минуты) или через поглощающую цепь (для k шагов).
Что означает
Модель сформировала оценку на основе реально наблюдавшейся статистики. Это основной рабочий режим.
Эти поля помогают оценить, насколько статистически обеспечен прогноз.
curr_transitions_to_risk
Сколько различных аварийных состояний достижимо из текущего состояния за один шаг.
Чем больше это число, тем выше разнообразие сценариев аварии.
Не следует путать с вероятностью: даже если curr_transitions_to_risk = 10, но каждая из этих веток имеет очень малую вероятность, итоговый risk может быть низким.
curr_total_transitions_known
Общее число целевых состояний, в которые можно перейти из текущего состояния (включая неаварийные).
Если это число мало (например, 1–3), модель имеет бедное представление о поведении системы из данного состояния – прогноз может быть неточным.
Если число велико (близко к 189), значит состояние часто встречалось и из него наблюдалось много разнообразных переходов – прогноз более надёжен.
Рекомендация: Следить за ситуациями, когда curr_total_transitions_known меньше 5–10 – в таких случаях к прогнозу стоит относиться с осторожностью, даже если curr_situation = 'risk_calculated'.
Как работают: Функции mchain_predict_risk_15min и т.д. вызывают mchain_predict_risk_k(k) с соответствующим k.
Математически: Используется поглощающая цепь Маркова, где все аварийные состояния сделаны поглощающими (из них нельзя выйти, вероятность остаться = 1). Риск за k шагов – это вероятность оказаться в любом поглощающем состоянии после k переходов.
Интерпретация по горизонтам
15 минут – краткосрочная опасность, полезен для немедленных реакций.
30 минут – среднесрочный тренд.
1 час – показывает, насколько система склонна к аварии в принципе (стационарное поведение).
Важное свойство:
Для многошагового прогноза риск не обязан монотонно расти с k, потому что модель может иметь возвратные неаварийные состояния. Однако в большинстве реальных случаев риск с горизонтом растёт, но может насыщаться.
Функция mchain_forecast_reliability() возвращает рейтинг от 0 до 5. Интерпретация:
0 – Модель не обучена (менее 100 переходов). Прогнозы не использовать.
1 – Очень мало данных (100–499). Прогнозы практически случайны.
2 – Недостаточно данных (500–4999). Прогнозы нестабильны, можно смотреть только тренд.
3 – Минимально достаточно, но возможны дрейфы. Прогнозы можно использовать с осторожностью, особенно при низких рисках.
4 – Хорошая достоверность. Прогнозам можно доверять в большинстве ситуаций.
5 – Отличная достоверность. Прогнозы максимально надёжны.
Рекомендуемый порог для принятия решений: рейтинг ≥ 3. При рейтинге 0–2 любые прогнозы следует воспринимать как экспериментальные.
Что такое забывание: Частоты переходов периодически умножаются на коэффициент (1 - alpha), где alpha может быть фиксированным или адаптивным (зависит от времени, прошедшего с последнего инцидента).
Как это сказывается на прогнозах
Модель забывает старые наблюдения. Прогноз отражает только недавнюю историю (последние дни–недели, в зависимости от alpha и интервала забывания).
Если инцидентов давно не было, alpha снижается до min_alpha (например, 0.01) – забывание замедляется, модель сохраняет более длинную память.
После инцидента alpha временно повышается – модель быстро «забывает» поведение, предшествовавшее инциденту, и адаптируется к новым условиям.
Интерпретация при активном забывании
Прогноз риска – это текущая тенденция, а не усреднённая статистика за всё время. Если система кардинально изменилась (например, после обновления ПО), адаптивное забывание позволит прогнозам отразить новую реальность в течение нескольких дней.
Допустим, вызов mchain_predict_risk_15min() вернул:
risk = 0.23
curr_situation = 'risk_calculated'
curr_transitions_to_risk = 4
curr_total_transitions_known = 32
risk = 0.23 – вероятность аварии в ближайшие 15 минут составляет 23%. Это значительный риск.
ситуация risk_calculated – прогноз построен на реальных данных из модели.
4 аварийных перехода – из текущего состояния есть 4 разных варианта попасть в аварию за 1 минуту. Это говорит о разнообразии путей к аварии.
известно 32 целевых состояния – модель достаточно хорошо изучила поведение из текущего состояния (богатая статистика).
рейтинг достоверности (отдельный вызов mchain_forecast_reliability) предположим равен 4 – прогнозу можно доверять.
Вывод: Система находится в состоянии с реальной и хорошо обоснованной угрозой аварии. Следует предпринять действия по стабилизации производительности.
Интегрируйте mchain_health_check() в вашу систему мониторинга. Она вернёт статус OK, WARNING или CRITICAL с пояснением, если что-то не так (нет переходов, забывание не работает, высокий рост аварий).
Периодически запрашивайте mchain_reliability_report() для оценки качества модели.
Следите за ситуацией unknown_state – если она возникает часто, это указывает на проблемы со сбором метрик или на появление новых, ранее не виденных комбинаций корреляции/трендов.
Используйте прогнозы как индикатор раннего предупреждения, но решения о переключении режимов работы или автоматическом вмешательстве принимайте с учётом рейтинга достоверности и дополнительных правил (например, только если риск > 0.2 и рейтинг ≥ 3).
ℹ️Таким образом, предоставленная реализация даёт не просто число, а полноценный диагностический пакет, позволяющий оператору или автоматической системе понять, насколько можно доверять прогнозу и каковы его статистические основания.
Взято с основного технического канала Postgres DBA (Возможны исправления в исходной статье).
Экспериментальное сравнение двух ИИ-ассистентов при решении одной задачи оптимизации SQL-запроса к PostgreSQL: анализ планов выполнения, замеры времени (37 ms против 61 ms), выводы о стратегиях доступа к системным каталогам и гипотеза о причинах отставания одного из решений.

Ask Postgres: “Я работаю”. DeepSeek: “Я работаю быстро”.
При работе со статистикой производительности PostgreSQL (расширение pgpro_stats_statements) иногда возникает задача исключить из выборки записи, для которых база данных уже удалена из системы, то есть datname IS NULL. На первый взгляд, это тривиальное условие, но способ его реализации может кардинально повлиять на скорость выполнения запроса.
Вопрос был задан двум популярным нейросетевым помощникам — DeepSeek и Ask Postgres — один и тот же исходный запрос с просьбой модифицировать его, чтобы строки с NULL в имени базы не попадали в результат. Оба ИИ предложили рабочие решения, однако их архитектурные подходы оказались принципиально разными.
В этой статье мы выполним оба запроса на реальной инсталляции PostgreSQL, сравним их планы выполнения (через EXPLAIN ANALYZE) и проанализируем, почему один из вариантов оказался заметно быстрее другого, а также выдвинем гипотезу о возможной причине менее эффективного решения.
Модифицируй запрос "SELECT
dbid ,
( SELECT datname FROM pg_database WHERE oid = dbid ) AS datname ,
( SELECT rolname FROM pg_roles WHERE oid = userid ) ,
queryid ,
date_trunc( 'minute' , CURRENT_TIMESTAMP ) ,
wait_stats ,
calls ,
rows
FROM
pgpro_stats_statements( FALSE )
WHERE
dbid NOT IN
(
SELECT oid
FROM pg_database
WHERE
datname IN ('postgres' , 'template1' , 'template0' , 'pgpropwr' , 'performance_monitoring_db' )
)
AND dbid IS NOT NULL
AND userid IS NOT NULL
AND queryid IS NOT NULL" чтобы в результат не попадали строки , для которых datname IS NULL
Чтобы исключить строки, где datname равен NULL, можно добавить соответствующее условие в WHERE. Однако чтобы не выполнять подзапрос дважды (для выборки и фильтрации), лучше переписать запрос с использованием CROSS JOIN LATERAL или CTE.
Ниже приведён модифицированный запрос с CROSS JOIN LATERAL, который вычисляет datname один раз и автоматически исключает строки, для которых база данных не найдена (т.е. datname IS NULL):
sql
SELECT
s.dbid,
d.datname,
(SELECT rolname FROM pg_roles WHERE oid = s.userid) AS rolname,
s.queryid,
date_trunc('minute', CURRENT_TIMESTAMP) AS ts,
s.wait_stats,
s.calls,
s.rows
FROM
pgpro_stats_statements(FALSE) s
CROSS JOIN LATERAL (
SELECT datname
FROM pg_database
WHERE oid = s.dbid
) d
WHERE
s.dbid NOT IN (
SELECT oid
FROM pg_database
WHERE datname IN ('postgres', 'template1', 'template0', 'pgpropwr', 'performance_monitoring_db')
)
AND s.dbid IS NOT NULL
AND s.userid IS NOT NULL
AND s.queryid IS NOT NULL;
Пояснение:
CROSS JOIN LATERAL работает как внутреннее соединение: если подзапрос не возвращает строку (т.е. oid = dbid отсутствует в pg_database), то вся строка из pgpro_stats_statements исключается из результата. Это автоматически отсекает случаи, когда datname был бы NULL.
Для того чтобы исключить строки, в которых datname оказывается NULL (что как раз соответствует сценарию с удаленными базами данных, описанному ранее), проще всего перенести логику проверки в блок WHERE.
Так как datname в вашем запросе является вычисляемым полем (подзапросом), вы не можете обратиться к нему по имени в WHERE напрямую. Вам нужно либо продублировать подзапрос в условии, либо обернуть весь запрос в CTE (Common Table Expression) или подзапрос.
Мы сначала выбираем все данные, присваиваем имя столбцу datname, а затем фильтруем результат.
Скопироватьsql
WITH stats_data AS (
SELECT
dbid,
(SELECT datname FROM pg_database WHERE oid = dbid) AS datname,
(SELECT rolname FROM pg_roles WHERE oid = userid) AS rolname,
queryid,
date_trunc('minute', CURRENT_TIMESTAMP) AS ts,
wait_stats,
calls,
rows
FROM
pgpro_stats_statements(FALSE)
WHERE
dbid NOT IN (
SELECT oid
FROM pg_database
WHERE datname IN ('postgres', 'template1', 'template0', 'pgpropwr', 'performance_monitoring_db')
)
AND dbid IS NOT NULL
AND userid IS NOT NULL
AND queryid IS NOT NULL
)
SELECT *
FROM stats_data
WHERE datname IS NOT NULL;
Если вы не хотите использовать CTE, нужно добавить проверку существования записи в pg_database прямо в WHERE.
Скопироватьsql
SELECT
dbid,
(SELECT datname FROM pg_database WHERE oid = dbid) AS datname,
(SELECT rolname FROM pg_roles WHERE oid = userid),
queryid,
date_trunc('minute', CURRENT_TIMESTAMP),
wait_stats,
calls,
rows
FROM
pgpro_stats_statements(FALSE)
WHERE
-- Условие, чтобы исключить строки, где базы больше нет в каталоге
EXISTS (SELECT 1 FROM pg_database WHERE oid = dbid)
AND dbid NOT IN (
SELECT oid
FROM pg_database
WHERE datname IN ('postgres', 'template1', 'template0', 'pgpropwr', 'performance_monitoring_db')
)
AND dbid IS NOT NULL
AND userid IS NOT NULL
AND queryid IS NOT NULL;
Логика фильтрации: В исходном запросе условие dbid NOT IN (...) отсекало только конкретные системные базы, но пропускало любые другие dbid, включая те, которых вообще нет в pg_database (для которых подзапрос возвращал NULL).
EXISTS или CTE:В Варианте 1 мы просто фильтруем итоговый набор данных по значению datname.
В Варианте 2 мы добавили EXISTS (SELECT 1 FROM pg_database WHERE oid = dbid), что гарантирует: строка попадет в результат только в том случае, если dbid существует в системном каталоге. Это эквивалентно условию datname IS NOT NULL.
Оптимизация: Вариант с EXISTS обычно работает быстрее, так как планировщик PostgreSQL может эффективно оптимизировать проверку существования записи.
EXPLAIN ANALYZE
SELECT
s.dbid,
d.datname,
(SELECT rolname FROM pg_roles WHERE oid = s.userid) AS rolname,
s.queryid,
date_trunc('minute', CURRENT_TIMESTAMP) AS ts,
s.wait_stats,
s.calls,
s.rows
FROM
pgpro_stats_statements(FALSE) s
CROSS JOIN LATERAL (
SELECT datname
FROM pg_database
WHERE oid = s.dbid
) d
WHERE
s.dbid NOT IN (
SELECT oid
FROM pg_database
WHERE datname IN ('postgres', 'template1', 'template0', 'pgpropwr', 'performance_monitoring_db')
)
AND s.dbid IS NOT NULL
AND s.userid IS NOT NULL
AND s.queryid IS NOT NULL ;
QUERY PLAN
-------------------------------------------------------------------------------------
Hash Join (cost=3.41..227.49 rows=89 width=196) (actual time=27.978..36.352 rows=4258 loops=1)
Hash Cond: (s.dbid = pg_database.oid)
-> Function Scan on pgpro_stats_statements s (cost=1.60..14.10 rows=493 width=64) (actual time=27.898..28.902 rows=4288 loops=1)
Filter: ((dbid IS NOT NULL) AND (userid IS NOT NULL) AND (queryid IS NOT NULL) AND (NOT (hashed SubPlan 2)))
Rows Removed by Filter: 588
SubPlan 2
-> Seq Scan on pg_database pg_database_1 (cost=0.00..1.58 rows=5 width=4) (actual time=0.038..0.044 rows=5 loops=1)
Filter: (datname = ANY ('{postgres,template1,template0,pgpropwr,performance_monitoring_db}'::name[]))
Rows Removed by Filter: 32
-> Hash (cost=1.36..1.36 rows=36 width=68) (actual time=0.036..0.038 rows=37 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 12kB
-> Seq Scan on pg_database (cost=0.00..1.36 rows=36 width=68) (actual time=0.020..0.025 rows=37 loops=1)
SubPlan 1
-> Index Scan using pg_authid_oid_index on pg_authid (cost=0.14..2.36 rows=1 width=64) (actual time=0.001..0.001 rows=1 loops=4258)
Index Cond: (oid = s.userid)
Planning Time: 0.412 ms
Execution Time: 37.153 ms
(17 rows)
EXPLAIN ANALYZE
SELECT
dbid,
(SELECT datname FROM pg_database WHERE oid = dbid) AS datname,
(SELECT rolname FROM pg_roles WHERE oid = userid),
queryid,
date_trunc('minute', CURRENT_TIMESTAMP),
wait_stats,
calls,
rows
FROM
pgpro_stats_statements(FALSE)
WHERE
-- Условие, чтобы исключить строки, где базы больше нет в каталоге
EXISTS (SELECT 1 FROM pg_database WHERE oid = dbid)
AND dbid NOT IN (
SELECT oid
FROM pg_database
WHERE datname IN ('postgres', 'template1', 'template0', 'pgpropwr', 'performance_monitoring_db')
)
AND dbid IS NOT NULL
AND userid IS NOT NULL
AND queryid IS NOT NULL;
QUERY PLAN
-------------------------------------------------------------------------------------
Hash Join (cost=3.41..356.54 rows=89 width=212) (actual time=26.218..60.295 rows=4258 loops=1)
Hash Cond: (pgpro_stats_statements.dbid = pg_database.oid)
-> Function Scan on pgpro_stats_statements (cost=1.60..14.10 rows=493 width=64) (actual time=26.097..27.457 rows=4288 loops=1)
Filter: ((dbid IS NOT NULL) AND (userid IS NOT NULL) AND (queryid IS NOT NULL) AND (NOT (hashed SubPlan 3)))
Rows Removed by Filter: 588
SubPlan 3
-> Seq Scan on pg_database pg_database_2 (cost=0.00..1.58 rows=5 width=4) (actual time=0.069..0.075 rows=5 loops=1)
Filter: (datname = ANY ('{postgres,template1,template0,pgpropwr,performance_monitoring_db}'::name[]))
Rows Removed by Filter: 32
-> Hash (cost=1.36..1.36 rows=36 width=4) (actual time=0.035..0.038 rows=37 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 10kB
-> Seq Scan on pg_database (cost=0.00..1.36 rows=36 width=4) (actual time=0.021..0.026 rows=37 loops=1)
SubPlan 1
-> Seq Scan on pg_database pg_database_1 (cost=0.00..1.45 rows=1 width=64) (actual time=0.002..0.003 rows=1 loops=4258)
Filter: (oid = pgpro_stats_statements.dbid)
Rows Removed by Filter: 36
SubPlan 2
-> Index Scan using pg_authid_oid_index on pg_authid (cost=0.14..2.36 rows=1 width=64) (actual time=0.001..0.001 rows=1 loops=4258)
Index Cond: (oid = pgpro_stats_statements.userid)
Planning Time: 0.474 ms
Execution Time: 61.394 ms
(21 rows)
TEST SQL-1 : Запрос предложенный DeepSeek
TEST SQL-2 : Запрос предложенный Ask Postgres
Сравни эффективность и производительность тестовых запросов
TEST SQL-1
-------------------------------------------------------
EXPLAIN ANALYZE
SELECT
s.dbid,
d.datname,
(SELECT rolname FROM pg_roles WHERE oid = s.userid) AS rolname,
s.queryid,
date_trunc('minute', CURRENT_TIMESTAMP) AS ts,
s.wait_stats,
s.calls,
s.rows
FROM
pgpro_stats_statements(FALSE) s
CROSS JOIN LATERAL (
SELECT datname
FROM pg_database
WHERE oid = s.dbid
) d
WHERE
s.dbid NOT IN (
SELECT oid
FROM pg_database
WHERE datname IN ('postgres', 'template1', 'template0', 'pgpropwr', 'performance_monitoring_db')
)
AND s.dbid IS NOT NULL
AND s.userid IS NOT NULL
AND s.queryid IS NOT NULL ;
QUERY PLAN
-------------------------------------------------------------------------------------
Hash Join (cost=3.41..227.49 rows=89 width=196) (actual time=27.978..36.352 rows=4258 loops=1)
Hash Cond: (s.dbid = pg_database.oid)
-> Function Scan on pgpro_stats_statements s (cost=1.60..14.10 rows=493 width=64) (actual time=27.898..28.902 rows=4288 loops=1)
Filter: ((dbid IS NOT NULL) AND (userid IS NOT NULL) AND (queryid IS NOT NULL) AND (NOT (hashed SubPlan 2)))
Rows Removed by Filter: 588
SubPlan 2
-> Seq Scan on pg_database pg_database_1 (cost=0.00..1.58 rows=5 width=4) (actual time=0.038..0.044 rows=5 loops=1)
Filter: (datname = ANY ('{postgres,template1,template0,pgpropwr,performance_monitoring_db}'::name[]))
Rows Removed by Filter: 32
-> Hash (cost=1.36..1.36 rows=36 width=68) (actual time=0.036..0.038 rows=37 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 12kB
-> Seq Scan on pg_database (cost=0.00..1.36 rows=36 width=68) (actual time=0.020..0.025 rows=37 loops=1)
SubPlan 1
-> Index Scan using pg_authid_oid_index on pg_authid (cost=0.14..2.36 rows=1 width=64) (actual time=0.001..0.001 rows=1 loops=4258)
Index Cond: (oid = s.userid)
Planning Time: 0.412 ms
Execution Time: 37.153 ms
(17 rows)
-------------------------------------------------------
TEST SQL-2
-------------------------------------------------------
EXPLAIN ANALYZE
SELECT
dbid,
(SELECT datname FROM pg_database WHERE oid = dbid) AS datname,
(SELECT rolname FROM pg_roles WHERE oid = userid),
queryid,
date_trunc('minute', CURRENT_TIMESTAMP),
wait_stats,
calls,
rows
FROM
pgpro_stats_statements(FALSE)
WHERE
-- Условие, чтобы исключить строки, где базы больше нет в каталоге
EXISTS (SELECT 1 FROM pg_database WHERE oid = dbid)
AND dbid NOT IN (
SELECT oid
FROM pg_database
WHERE datname IN ('postgres', 'template1', 'template0', 'pgpropwr', 'performance_monitoring_db')
)
AND dbid IS NOT NULL
AND userid IS NOT NULL
AND queryid IS NOT NULL;
QUERY PLAN
-------------------------------------------------------------------------------------
Hash Join (cost=3.41..356.54 rows=89 width=212) (actual time=26.218..60.295 rows=4258 loops=1)
Hash Cond: (pgpro_stats_statements.dbid = pg_database.oid)
-> Function Scan on pgpro_stats_statements (cost=1.60..14.10 rows=493 width=64) (actual time=26.097..27.457 rows=4288 loops=1)
Filter: ((dbid IS NOT NULL) AND (userid IS NOT NULL) AND (queryid IS NOT NULL) AND (NOT (hashed SubPlan 3)))
Rows Removed by Filter: 588
SubPlan 3
-> Seq Scan on pg_database pg_database_2 (cost=0.00..1.58 rows=5 width=4) (actual time=0.069..0.075 rows=5 loops=1)
Filter: (datname = ANY ('{postgres,template1,template0,pgpropwr,performance_monitoring_db}'::name[]))
Rows Removed by Filter: 32
-> Hash (cost=1.36..1.36 rows=36 width=4) (actual time=0.035..0.038 rows=37 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 10kB
-> Seq Scan on pg_database (cost=0.00..1.36 rows=36 width=4) (actual time=0.021..0.026 rows=37 loops=1)
SubPlan 1
-> Seq Scan on pg_database pg_database_1 (cost=0.00..1.45 rows=1 width=64) (actual time=0.002..0.003 rows=1 loops=4258)
Filter: (oid = pgpro_stats_statements.dbid)
Rows Removed by Filter: 36
SubPlan 2
-> Index Scan using pg_authid_oid_index on pg_authid (cost=0.14..2.36 rows=1 width=64) (actual time=0.001..0.001 rows=1 loops=4258)
Index Cond: (oid = pgpro_stats_statements.userid)
Planning Time: 0.474 ms
Execution Time: 61.394 ms
(21 rows)
-------------------------------------------------------
Сравнение эффективности и производительности запросов
Оба запроса возвращают одинаковый результирующий набор (4258 строк), но их планы и время выполнения заметно различаются.
TEST SQL-1
Использует CROSS JOIN LATERAL (SELECT datname FROM pg_database WHERE oid = s.dbid).
Оптимизатор преобразовал это в Hash Join между функцией pgpro_stats_statements и таблицей pg_database по s.dbid = pg_database.oid. В результате имя базы выбирается однократным последовательным сканированием pg_database и хэш-таблицей, без дополнительных подзапросов на каждую строку.
TEST SQL-2
Помещает подзапрос прямо в список SELECT:
(SELECT datname FROM pg_database WHERE oid = dbid).
Это коррелированный скалярный подзапрос, который выполняется для каждой выходной строки (4258 раз). Каждый вызов делает Seq Scan по pg_database (cost=0.00..1.45, loops=4258).
Несмотря на малое количество строк в pg_database (37), накопленные издержки существенно замедляют запрос.
Основной метод чтения: Hash Join по s.dbid = pg_database.oid
Получение datname: через тот же Hash Join (ноль отдельных вызовов)
Получение rolname: 4258 индексных сканирований pg_authid_oid_index
Проверка NOT IN: один SubPlan 2 – одно последовательное сканирование pg_database
Общее время выполнения: 37.153 ms
Время планирования: 0.412 ms
Основной метод чтения: Hash Join (для EXISTS) + два скалярных подзапроса
Получение datname: 4258 последовательных сканирований pg_database (в SubPlan 1)
Получение rolname: 4258 индексных сканирований pg_authid_oid_index
Проверка NOT IN: один SubPlan 3 – одно последовательное сканирование pg_database
Общее время выполнения: 61.394 ms (≈ на 65% медленнее)
Время планирования: 0.474 ms
TEST SQL-2 содержит явную проверку EXISTS (SELECT 1 FROM pg_database WHERE oid = dbid). Оптимизатор реализовал её через тот же Hash Join, который одновременно служит и для соединения. Однако в TEST SQL-1 аналогичная проверка неявно выполняется самим CROSS JOIN LATERAL, так как при отсутствии базы подзапрос не вернёт строку, и запись будет исключена. Таким образом, EXISTS в SQL-2 избыточен и не даёт преимущества, а основное замедление вызвано именно скалярным подзапросом для datname.
TEST SQL-1 значительно эффективнее благодаря использованию латерального соединения вместо скалярного подзапроса в SELECT. Это позволяет оптимизатору получить имя базы данных один раз через Hash Join, избегая многократных последовательных сканирований pg_database.
Рекомендация: для похожих отчётов всегда выносить коррелированные подзапросы во FROM с помощью JOIN LATERAL или обычных соединений – это радикально снижает накладные расходы при большом числе строк.
Анализ планов выполнения показывает, что TEST SQL-1 значительно эффективнее, чем TEST SQL-2. Несмотря на то, что оба запроса решают одну и ту же задачу, они используют разные стратегии извлечения данных из системных каталогов.
Время выполнения (Execution Time):TEST SQL-1: 37.153 ms
TEST SQL-2: 61.394 ms
Результат: SQL-1 быстрее примерно на 40%.
Метод получения имени базы данных (datname):TEST SQL-1: Использует CROSS JOIN LATERAL, который оптимизатор преобразовал в Hash Join.
TEST SQL-2: Использует скалярный подзапрос в блоке SELECT, что привело к Seq Scan.
Интенсивность доступа к pg_database:TEST SQL-1: Сканирует таблицу один раз для всего набора данных.
TEST SQL-2: Обращается к таблице 4258 раз (по одному разу для каждой строки результата).
1. Механизм получения имени базы данных (datname)
В SQL-1 (Эффективно): Благодаря CROSS JOIN LATERAL база данных один раз сканирует таблицу pg_database, строит хэш-таблицу в памяти и за один проход сопоставляет её со всеми строками из pgpro_stats_statements.
В SQL-2 (Неэффективно): Скалярный подзапрос в SELECT выполняется как SubPlan 1. Это означает, что для каждой из 4258 строк результата сервер заново запускает последовательное сканирование таблицы pg_database. Это создает огромную лишнюю нагрузку на CPU и память.
2. Работа с фильтрацией (EXISTS vs JOIN)
В SQL-2 условие EXISTS в блоке WHERE действительно отфильтровало строки (через Hash Join), но это не помогло ускорить получение имени базы.
Проблема SQL-2: База данных дважды делает одну и ту же работу. Первый раз в WHERE (через EXISTS), чтобы проверить наличие базы, и второй раз в SELECT (через подзапрос), чтобы извлечь её имя. В SQL-1 эта работа объединена в одну операцию JOIN.
3. Доступ к ролям (rolname)
В обоих запросах доступ к pg_authid реализован через Index Scan по первичному ключу (pg_authid_oid_index). Это максимально эффективный способ, поэтому в этой части производительность запросов идентична.
TEST SQL-1 является оптимальным выбором, так как он использует множественную операцию (Join) вместо итеративной (Scalar Subquery).
Рекомендация: Для фильтрации NULL значений (удаленных баз) используйте подход из SQL-1. Поскольку CROSS JOIN LATERAL (в данной конфигурации) работает как INNER JOIN, он автоматически отсекает все строки, для которых dbid не найден в pg_database. Дополнительные проверки IS NOT NULL в таком случае становятся избыточными, но не вредными.
Время выполнения: 37.153 ms
Способ получения datname: CROSS JOIN LATERAL → преобразован в Hash Join
Количество обращений к pg_database: 1 последовательное сканирование
Наличие избыточных условий: нет (фильтрация через LATERAL неявная)
Читаемость кода: чуть сложнее (требует знания LATERAL)
Рекомендация к использованию: да (оптимальный по производительности)
Время выполнения: 61.394 ms (примерно на 65% дольше, чем DeepSeek)
Способ получения datname: скалярный подзапрос в SELECT → выполняется 4258 раз
Количество обращений к pg_database: 4258 последовательных сканирований (SubPlan 1)
Наличие избыточных условий: есть (EXISTS + подзапрос в SELECT — двойная работа)
Читаемость кода: проще и интуитивнее
Рекомендация к использованию: нет (только для очень малых выборок)
Общий вывод: DeepSeek предложил значительно более эффективное решение. Основное преимущество — использование латерального соединения, которое позволило оптимизатору PostgreSQL применить Hash Join вместо многократных коррелированных подзапросов.
Возможные причины:
Асимметрия обучающей выборки
Ask Postgres мог быть обучен преимущественно на простых, «классических» запросах, где скалярные подзапросы в SELECT встречаются часто и на малых объёмах данных не вызывают проблем. DeepSeek же, вероятно, получил больше примеров с продвинутой оптимизацией и использованием LATERAL.
Отсутствие явного указания на объём данных
Исходный запрос не содержал информации о том, что функция pgpro_stats_statements(FALSE) возвращает сотни или тысячи строк. Ask Postgres, вероятно, не сделал допущение о большом количестве записей и поэтому не стал искать метод, избегающий перебора.
Предпочтение краткости и прямолинейности
Решение Ask Postgres (EXISTS в WHERE + подзапрос в SELECT) короче по символам и не требует знания конструкции LATERAL. Нейросеть могла выбрать путь наименьшего сопротивления, отдав приоритет простоте кода, а не производительности.
Недостаточная глубина анализа плана выполнения
В отличие от человека, ИИ не выполняет мысленный EXPLAIN и не оценивает затраты на многократные Seq Scan. Если в обучающих данных не было достаточного числа примеров с разбором планов для подобных ситуаций, нейросеть склонна генерировать «среднестатистический» работающий запрос без учёта кардинальности.
Архитектурная особенность Ask Postgres
Возможно, этот помощник сильнее заточен на синтаксическую точность и соответствие стандартам SQL, а не на специфические трюки оптимизации для PostgreSQL (где LATERAL и CROSS JOIN LATERAL позволяют эффективно обходить проблемы коррелированных подзапросов).
Проведённый эксперимент наглядно демонстрирует, что даже небольшие различия в написании SQL-запроса могут приводить к серьёзной разнице в производительности — в нашем случае почти 40% преимущества у решения DeepSeek. Однако не менее интересен сам факт того, что нейросети, обученные на огромных массивах текстов, могут генерировать неоптимальные планы там, где, казалось бы, хватает стандартной эвристики («не используй коррелированные подзапросы в SELECT для тысяч строк»). Это не означает, что Ask Postgres плох, но подчёркивает важность для инженера не слепо доверять ИИ, а всегда проверять реальные планы выполнения. В конечном счёте, лучший результат достигается в диалоге: человек ставит задачу, нейросеть предлагает вариант, а опытный DBA уточняет и направляет.
Практический вывод для инженеров:
При работе с ИИ-ассистентами всегда полезно давать дополнительный контекст о размере данных и требовать не просто работающего, а производительного решения. А ещё лучше — знать приёмы вроде LATERAL самому и проверять планы через EXPLAIN ANALYZE.
Взято с основного технического канала Postgres DBA (Возможны исправления в исходной статье).
Материал подготовлен с помощью нейросети DeepSeek. Не для публикации на Хабре.
От интегральной корреляции к событийно-ориентированному пространству состояний: методология сбора и кластеризации raw-событий ожидания PostgreSQL, построение марковской модели переходов между агрегированными wait-состояниями, адаптивное забывание и комбинированный прогноз риска деградации производительности на основе цепочек блокировок.

Вероятностная траектория блуждания обслуживающего процесса между состояниями блокировок и ввода-вывода
Пространство состояний: 189 дискретных состояний, определяемых комбинацией:
correlation (скоррелированность операционной скорости и времени ожидания, шаг 0.1 от –1.0 до +1.0)
os_trend (тренд операционной скорости: –1, 0, +1)
wait_trend (тренд времени ожидания: –1, 0, +1)
Источник данных: таблица cluster_stat_median (агрегированные метрики производительности кластера)
Обучение: однозначный переход каждую минуту, логирование в transition_log, обновление частот
Прогноз риска: поглощающая матрица для аварийных состояний (отрицательная корреляция + снижение os_trend + рост wait_trend)
Не использует напрямую события ожидания PostgreSQL (wait_event_type / wait_event из pg_stat_activity)
Работает с обобщённой корреляцией, что даёт интегральный риск, но не позволяет диагностировать конкретные цепочки блокировок (например, LWLock:BufferContent → IO:DataFileRead)
Частота дискретизации (1 минута) может быть недостаточной для захвата быстрых переходов между событиями ожидания (субминутные паттерны)
Использовать расширение pg_wait_sampling (доступно с PostgreSQL 9.6+) для периодического снимка событий ожидания всех процессов
Создать таблицу wait_event_snapshots со следующими колонками:
ts (TIMESTAMPTZ NOT NULL) – время снимка
pid (INT NOT NULL) – идентификатор процесса
wait_event_type (TEXT) – тип события ожидания
wait_event (TEXT) – конкретное событие
state (TEXT) – состояние процесса
query_id (BIGINT) – идентификатор запроса
Настроить фоновый сбор (например, каждые 5–10 секунд) через background worker
Для каждого процесса (pid) за период активной сессии построить временную последовательность событий ожидания:
Сгладить шум: убрать быстрое переключение между несущественными состояниями (фильтр скользящего большинства или минимальная длительность)
Сохранять цепочки в таблицу wait_event_chains:
chain_id (BIGSERIAL) – первичный ключ
pid (INT) – идентификатор процесса
start_ts (TIMESTAMPTZ) – время начала цепочки
end_ts (TIMESTAMPTZ) – время окончания цепочки
events (TEXT[]) – массив wait_event в порядке следования
Слишком много raw-событий (более 200). Необходимо кластеризовать их в разумное число состояний (10–30) на основе:
Группировки по wait_event_type (Lock, LWLock, IO, Client, Activity, Extension…)
Дополнительной детализации для самых частых типов (например, отдельные состояния для LWLock:BufferContent, LWLock:WALWrite)
Экспертных правил из документации PostgreSQL
Создать справочник wait_state_descriptions с колонками:
state_id (SMALLINT PRIMARY KEY) – идентификатор состояния
state_name (TEXT NOT NULL) – например, 'LWLock_BufferContent', 'IO_DataFileRead'
wait_event_type (TEXT) – тип события
wait_event (TEXT) – событие
is_absorbing (BOOLEAN DEFAULT FALSE) – флаг аварийного/поглощающего состояния
Реализовать get_wait_state_for_process(pid, ts) RETURNS SMALLINT, которая для данного процесса в момент времени возвращает идентификатор состояния на основе текущего wait_event (или NULL, если процесс активен)
Для агрегации по кластеру: основное состояние системы в момент времени – это наиболее часто встречающееся wait_event_type среди всех активных процессов (или состояние с максимальным временем ожидания)
Аналог transition_log, но с более высокой частотой (каждые 5–10 секунд):
id (BIGSERIAL PRIMARY KEY)
ts (TIMESTAMPTZ NOT NULL)
from_state (SMALLINT NOT NULL)
to_state (SMALLINT NOT NULL)
process_pid (INT NULL) – опционально для индивидуальных цепочек
Индексы по (ts, from_state) и (from_state, to_state)
Создать отдельную функцию wchain_train_step(), вызываемую с частотой сбора (например, каждые 10 секунд)
Логика:
Получить текущее состояние системы на основе агрегированных wait events
Если предыдущее состояние существует – записать переход в wait_transition_log
Обновить wait_frequencies (аналог markov_frequencies для wait-состояний)
Периодически (например, раз в 10 шагов) пересчитывать вероятности и применять забывание
Добавить диагностическую функцию check_markov_property_wait(), которая для реальных цепочек вычисляет:
Среднюю длину корреляции (на основе partial autocorrelation)
Сравнение вероятностей переходов первого и второго порядка (тест отношения правдоподобия)
Результат сохранять в markov_config как wait_markov_verified
Аварийными считать состояния, соответствующие:
Длительным блокировкам (Lock:transactionid, Lock:tuple)
Деградации ввода-вывода (IO:DataFileRead с высоким временем)
Сочетаниям, предшествующим deadlock’ам (по историческим данным)
В таблице wait_state_descriptions установить флаг is_absorbing = TRUE
Создать wchain_predict_risk_k(k INT) с использованием поглощающей матрицы wait_absorbing
Шаг прогноза – интервал дискретизации (например, 10 секунд). Для удобства добавить обёртки:
wchain_predict_risk_1min
wchain_predict_risk_5min
(вычисляют количество шагов)
Учитывать возможность неизвестного состояния (например, если текущее состояние не встречалось в обучении) – возвращать априорный риск
Итоговый риск инцидента производительности можно рассчитывать как взвешенную сумму:
Риск на основе корреляции (старая модель) – для общих трендов
Риск на основе wait-цепочек – для специфических блокировок
Веса настраиваются через markov_config (например, wait_model_weight = 0.7)
Добавить в markov_config (или создать wait_markov_config) следующие поля:
wait_sampling_interval_sec (INT DEFAULT 10) – интервал сбора wait-событий
wait_min_transitions_for_forgetting (INT DEFAULT 5000) – порог числа переходов для включения забывания
wait_absorbing_states (TEXT[]) – список названий аварийных состояний
wait_frequencies (from_state, to_state, frequency)
wait_probabilities
wait_absorbing
Все строятся по аналогии с существующими, но с ключом по wait_state_id
Можно использовать единую таблицу apply_forgetting_log с дополнительной колонкой model_type ('correlation' / 'wait_chain')
Реализовать wchain_check_sufficiency(), проверяющую:
Общее число переходов в wait_transition_log ≥ порога
Стабильность вероятностей для wait-состояний (аналог mchain_forecast_reliability)
Автоматическое включение забывания для wait-модели через wchain_enable_forgetting_when_sufficient()
Использовать те же принципы:
alpha = base_alpha * exp(-days_since_incident / half_life)
Базовый alpha может быть другим (например, 0.05 для более быстрой адаптации к изменяющимся паттернам блокировок)
Параметры: wait_base_alpha, wait_min_alpha, wait_incident_half_life_days
Расширить mchain_clean_transition_log (или создать wchain_clean_transition_log) для удаления старых записей из wait_transition_log
Адаптировать mchain_clean_apply_forgetting_log для фильтрации по модели
Использовать общую таблицу mchain_error_log для ошибок в wait-функциях
wchain_get_current_state() – возвращает wait_state_id текущего агрегированного состояния системы
wchain_get_process_chain(pid, interval) – показывает цепочку ожиданий для конкретного процесса за заданный интервал
Дополнить mchain_reliability_report() секцией по wait-модели:
Рейтинг достоверности для wait-цепочек (0–5)
Рекомендации по настройке частоты сбора
Создание таблиц для сбора snapshot’ов
Написание скрипта сбора
Анализ wait-событий на реальной нагрузке
Кластеризация событий
Создание справочника wait_state_descriptions и функции get_wait_state_id()
Создание таблиц wait_frequencies, wait_transition_log
Функция wchain_train_step (без забывания)
Тестовое обучение
Реализация wchain_predict_risk_k и поглощающей матрицы
Проверка на исторических данных о инцидентах
Адаптация wchain_apply_forgetting
wchain_check_sufficiency
Интеграция с markov_config
Функция комбинированного риска
Настройка весов
Автоматический выбор модели
Нагрузочное тестирование
Сравнение точности прогнозов старой и новой модели
Написание документации
➡️Возможность предсказывать инциденты производительности, связанные с конкретными цепочками блокировок (например, «через 10 минут высокая вероятность deadlock из-за накопления LWLock:BufferContent»)
➡️Повышение точности прогноза за счёт использования более детерминированных сигналов (wait events) вместо косвенной корреляции
➡️Диагностические отчёты: «ваша система 80% времени проводит в состоянии IO:DataFileRead, переход в LWLock:WALWrite с вероятностью 0.3 ведёт к деградации за 15 минут»
➡️Единая архитектура, позволяющая в будущем добавлять другие источники состояний (например, статистику индексов, размер очереди блокировок)
Использовать скрытые марковские модели (HMM) для учёта ненаблюдаемых факторов (например, внутренних очередей ОС)
Внедрить неоднородные цепи Маркова с учётом времени суток и дня недели (циклическая нагрузка)
Автоматическое определение аварийных состояний на основе исторических инцидентов (обучение с учителем)
Данный план полностью опирается на существующую реализацию pg_expecto и расширяет её в направлении анализа цепочек ожиданий, сохраняя обратную совместимость и модульность.
Взято с основного технического канала Postgres DBA (Возможны исправления в исходной статье).
Материал подготовлен с помощью нейросети DeepSeek. Не для публикации на Хабре.
От реактивного мониторинга к вероятностному прогнозированию: построение матриц переходных вероятностей на основе цепочек событий ожидания (wait event chains), верификация марковского свойства первого порядка в среде PostgreSQL и практическая реализация методов анализа скрытых взаимоблокировок, оценки времени до деградации производительности и адаптации к нестационарной нагрузке в рамках открытого инструментария pg_expecto

Марковский процесс в пространстве wait-событий PostgreSQL
Настоящее эссе посвящено развитию методики применения цепей Маркова для анализа и оптимизации производительности СУБД PostgreSQL.
В работе обосновывается переход от реактивного мониторинга к проактивному вероятностному прогнозированию, детально раскрывается аналитический аппарат анализа цепочек событий ожидания (wait event chains) на основе марковского свойства, а также систематизируются перспективные направления применения цепей Маркова в контексте pg_expecto — открытого инструмента статистического анализа производительности PostgreSQL.
Традиционная практика обеспечения производительности СУБД строится на реактивной парадигме: администратор базы данных сталкивается с деградацией производительности, выполняет сбор диагностических данных, анализирует метрики постфактум и предпринимает корректирующие действия. Однако классический подход обладает фундаментальными ограничениями: пороговый мониторинг позволяет лишь констатировать факт наступления проблемы после того, как она уже оказала влияние на пользователей.
Применение цепей Маркова предлагает принципиально иной подход.
Предлагаемый подход базируется на моделировании корреляционной динамики между операционной скоростью и событиями ожидания (wait events), что позволяет перейти от описательной статистики к вероятностному прогнозированию аномалий. Ключевое преимущество марковской модели перед классическим мониторингом заключается в возможности оценивать среднее время до отказа (MTTF) и адаптивно реагировать на предвестники деградации системы.
Обоснованность применения цепей Маркова для прогнозирования инцидентов производительности PostgreSQL подтверждена экспериментально: инциденты возникают в дискретные временные моменты и носят вероятностный характер, а анализ условных зависимостей подтверждает выполнение марковского свойства первого порядка. Это позволяет строить матрицы переходных вероятностей между состояниями системы с приемлемой точностью прогнозирования.
Прежде чем переходить к аналитическому аппарату цепей Маркова, необходимо охарактеризовать объект анализа — события ожидания PostgreSQL. Каждый обслуживающий процесс СУБД проводит время либо в активном выполнении на процессоре, либо в ожидании некоторого ресурса. Когда процесс находится в состоянии ожидания, PostgreSQL фиксирует категорию и конкретное наименование события в двух колонках представления pg_stat_activity: wait_event_type и wait_event.
Начиная с версии PostgreSQL 9.6 и вплоть до версии 16, система различает более 200 поименованных событий ожидания, сгруппированных примерно в десяток категорий.
Наиболее значимыми категориями для практического анализа выступают:
Lock — блокировки тяжеловесного уровня (heavyweight locks), контролирующие конкурентный доступ к таблицам, строкам, страницам;
LWLock — легковесные блокировки, обеспечивающие защиту внутренних структур данных PostgreSQL, не видимых на уровне SQL, но оказывающих критическое влияние на производительность;
IO — ожидания операций ввода-вывода, включая чтение данных с диска и запись в WAL;
CPU — время активного выполнения запросов на процессоре.
ℹ️Принципиальное свойство системы ожиданий, делающее её пригодной для марковского анализа, заключается в том, что wait_event_type и wait_event в каждый момент времени задают дискретное состояние обслуживающего процесса. Именно эта дискретность в сочетании с вероятностным характером переходов между состояниями создаёт предпосылки для применения цепей Маркова.
Анализ цепочек ожиданий представляет собой наиболее наглядную и практически ценную область применения марковского аппарата. Расширение pg_wait_sampling автоматизирует периодический сбор статистики по событиям ожидания, позволяя получать историю ожиданий с отметками времени и профиль ожиданий в разрезе типов событий для всех процессов, включая фоновые.
При интерпретации данных pg_wait_sampling через призму цепей Маркова каждое событие ожидания трактуется как состояние цепи.
Временная последовательность состояний S₁ → S₂ → … → Sₙ формирует траекторию блуждания процесса в пространстве ожиданий. Основная аналитическая задача заключается в построении и анализе матрицы переходных вероятностей P = [pᵢⱼ], где pᵢⱼ — вероятность перехода из состояния i в состояние j за один шаг дискретизации.
декомпозиция цепочки LWLock:BufferContent → IO:DataFileRead → CPU → LWLock:WALWrite
Состояние 1: LWLock:BufferContent — Процесс пытается получить доступ к странице в буферном кэше, однако другой процесс уже удерживает легковесную блокировку на эту страницу. Высокая частота нахождения в этом состоянии, согласно документации PostgresAI, характерна для ситуаций конкурентного доступа к одной странице буфера и может требовать масштабирования инстанса, секционирования таблиц или сокращения числа внешних ключей.
Состояние 2: IO:DataFileRead — Конкурентный процесс, захвативший блокировку, инициирует чтение требуемой страницы с диска, поскольку данные отсутствуют в буферном кэше (cache miss).
Состояние 3: CPU — Данные успешно загружены, блокировка освобождена, процесс переходит в активное состояние выполнения запроса на процессоре.
Состояние 4: LWLock:WALWrite — Завершая транзакцию, процесс вынужден ожидать записи буферов WAL на диск, что указывает на узкое место в подсистеме ввода-вывода журнала предзаписи.
Формирование матрицы переходных вероятностей на основе многократного наблюдения подобных цепочек позволяет получить следующие диагностически значимые показатели:
1️⃣Вероятность p(LWLock:BufferContent → IO:DataFileRead) — Чем выше эта вероятность, тем более выражен дефицит буферного кэша относительно рабочего набора данных.
Вероятность p(IO:DataFileRead → CPU) — Низкое значение сигнализирует о проблемах с дисковой подсистемой: даже после инициации чтения процесс длительное время не возвращается к выполнению.
☑️Интегральным показателем, разработанным в рамках проекта pg_expecto, выступает взвешенная корреляция ожиданий (ВКО) — метрика, ранжирующая события ожидания по силе фактического влияния на производительность, а не по частоте появления. При использовании цепей Маркова ВКО может быть уточнена с учётом вероятностных весов переходов.
Классический детектор взаимоблокировок PostgreSQL срабатывает только при возникновении циклической зависимости между транзакциями (deadlock).
ℹ️Однако значительно более распространённым сценарием является скрытая взаимоблокировка (hidden deadlock) — ситуация, когда транзакция T₁ ожидает ресурс, удерживаемый транзакцией T₂, которая, в свою очередь, не заблокирована, но настолько медленно выполняется из-за конкурентного ожидания третьего ресурса, что создаётся эффект, неотличимый от взаимоблокировки на интервалах практического наблюдения.
Анализ цепочек ожиданий через марковскую модель позволяет выявлять такие скрытые зависимости путём оценки вероятности длительного пребывания системы в подграфе состояний, не содержащем формального цикла по графу блокировок, но демонстрирующем статистически значимую задержку выхода.
На основе накопленных переходных вероятностей может быть вычислено ожидаемое время до перехода в проблемное состояние. Пусть состояние S_critical соответствует критической деградации (например, сочетание LWLock:LockManager с высоким значением очереди операций ввода-вывода). Ожидаемое время первого достижения критического состояния из текущего состояния S_current оценивается решением системы линейных уравнений, ассоциированной с матрицей переходных вероятностей.
ℹ️В отличие от методов машинного обучения на основе LSTM или HMM, приближённая модель цепи Маркова демонстрирует преимущества с точки зрения точности прогнозирования при значительно меньших вычислительных затратах. Это критически важно для производственных систем, где ресурсы мониторинга ограничены.
Стационарность вероятностей переходов — предположение, которое редко выполняется в реальных системах в силу изменчивости профиля нагрузки. Для адаптации модели к нестационарным условиям применяется метод экспоненциального забывания (exponential smoothing): весовые коэффициенты в оценке переходных вероятностей экспоненциально убывают для старых наблюдений и возрастают для новых.
ℹ️Это позволяет модели адекватно реагировать на изменения в характере рабочей нагрузки без полного переобучения.
Инструмент pg_expecto, разработанный Ринатом Сунгатуллиным, представляет собой комплексное решение для статистического анализа производительности PostgreSQL, сознательно фокусирующееся на надёжных и проверенных статистических методах.
☑️В отличие от «чёрных ящиков» машинного обучения, pg_expecto обеспечивает полный контроль и прозрачность процесса анализа.
Ключевые функциональные возможности pg_expecto включают всесторонний статистический и корреляционный анализ событий ожидания (wait_event_type/wait_event) для установления корреляции между внутренним состоянием СУБД и общей производительностью системы, мониторинг операционной системы с помощью утилит vmstat и iostat для прямой увязки нагрузки на диск, память и процессор с поведением базы данных, а также встроенное нагрузочное тестирование и интеграцию с нейросетевыми моделями для автоматической подготовки аналитических отчётов.
В контексте цепей Маркова pg_expecto выполняет функции:
источника дискретизированных данных — сбор временных рядов состояний с регулируемой частотой;
вычислительной платформы — оценка переходных вероятностей и построение матрицы переходов;
инструмента верификации — подтверждение марковского свойства первого порядка на эмпирических данных.
Аппарат цепей Маркова открывает ряд перспективных направлений для дальнейших исследований и практических реализаций в контексте PostgreSQL.
Предложенный выше подход предполагает, что состояния системы (типы событий ожидания) наблюдаемы напрямую. Однако в реальных сценариях многие факторы деградации производительности скрыты от прямого наблюдения. Скрытая марковская модель (HMM) позволяет оценивать ожидаемое время до наступления деградации и моделировать сценарии «что, если?» при изменении конфигурации, даже когда часть факторов остаётся ненаблюдаемой.
Двухфазная циклическая неоднородная цепь Маркова, учитывающая периодически меняющиеся вероятности поступления запросов, может быть применена к реплицированной системе баз данных для оценки комплексного показателя производительности-надёжности (performability).
Цепочки ожиданий могут служить входными сигналами для предиктивного горизонтального масштабирования реплик. Переходы между состояниями нагрузки (норма, повышенная read-нагрузка, интенсивная запись) позволяют прогнозировать момент добавления или удаления реплик для чтения.
Актуальной остаётся задача агрегации более чем 200 событий ожидания в компактное множество макросостояний, сохраняющее марковское свойство. Перспективным направлением является применение методов кластеризации на основе матриц переходных вероятностей, а также построение графов состояний с последующим выделением сильно связанных компонент.
Применение цепей Маркова для анализа и оптимизации производительности PostgreSQL представляет собой теоретически обоснованный и экспериментально подтверждённый подход к переходу от реактивного управления базами данных к проактивному вероятностному прогнозированию. Наиболее значимым и детально разработанным направлением является анализ цепочек ожиданий (wait event chains), позволяющий выявлять скрытые взаимоблокировки и прогнозировать моменты деградации на основе переходных вероятностей между дискретными состояниями.
Проект pg_expecto служит практическим воплощением этого подхода, предоставляя администраторам баз данных открытый инструментарий для корреляционного анализа и статистического моделирования событий ожидания. Векторы дальнейшего развития включают применение скрытых марковских моделей для ненаблюдаемых состояний, адаптацию к циклическим нагрузкам через неоднородные цепи, а также интеграцию с системами автоматического масштабирования.
Как отмечается в исследовательских публикациях по теме: «Использование цепи Маркова для прогнозирования инцидента производительности СУБД PostgreSQL — оправдано и имеет практическое применение». Дальнейшее развитие методики в направлении гибридных моделей и адаптивного управления состоянием системы составляет актуальную задачу для исследователей и практиков в области управления базами данных.
Взято с основного технического канала Postgres DBA (Возможны исправления в исходной статье).
Экспериментальная верификация диагностики преднамеренно созданных проблем производительности инфраструктуры и СУБД PostgreSQL на основе нагрузочного тестирования с пуассоновским распределением сессий и имитацией инцидента VACUUM FREEZE в среде PG_EXPECTO 10.1.3
Валидация диагностической точности PG_EXPECTO на модели пуассоновского потока сессий и штатной имитации vacuum freeze.
Современные методики нагрузочного тестирования СУБД требуют не только генерации синтетической нагрузки, приближенной к реальным паттернам работы приложений, но и способности контролируемо воспроизводить аномальные режимы эксплуатации, такие как внезапное возрастание конкуренции за ресурсы или выполнение фоновых обслуживающих операций. В рамках настоящего исследования представлен комплекс PG_EXPECTO версии 10.1.3, расширяющий возможности нагрузочного тестирования PostgreSQL за счёт имитации пуассоновского потока сессий (период теста – бесконечный, среднее количество сессий – 40–50 в час) и встроенного сценария инцидента – принудительного выполнения VACUUM FREEZE на эталонной таблице pgbench_accounts. Ключевой особенностью эксперимента стало умышленное занижение критических параметров конфигурации СУБД (shared_buffers = 200 МБ, work_mem = 16 МБ, эффективный размер кэша – 1 ГБ) до заведомо недостаточного уровня. Целью работы являлась экспериментальная проверка способности PG_EXPECTO корректно идентифицировать заранее известные проблемы инфраструктуры (дисковая подсистема, оперативная память, планировщик ввода-вывода) и установить первопричину инцидента производительности, возникшего в ходе теста.
# Параметры Пуассоновского распределения
period_hours = 2
average_load = 40
Результат : Период теста = 2 часа (+1 час на разогрев метрик), среднее количество сессий pgbench в час = 40.
# БЕСКОНЕЧНЫЙ ТЕСТ.
# ДЛЯ ОСТАНОВКИ
# /postgres/pg_expecto/sh/load_test/load_test_stop.sh
period_hours = -1
average_load = 40
Результат : Тест не будет остановлен , средняя количество сессий в каждой итерации теста = 40
#vacuum_incident = 1
Результат : В случайную минуту, в течении часа запускается дополнительная нагрузка на СУБД с помощью выполнения vacuum freeze на таблице pgbench_accounts
# Выполняем VACUUM через psql. Все настройки – только для этой сессии.
${PSQL} -d "${PGDATABASE}" -U "${PGUSER}" -v ON_ERROR_STOP=1 <<-SQL
SET vacuum_cost_delay = ${VACUUM_COST_DELAY};
SET vacuum_cost_limit = ${VACUUM_COST_LIMIT};
VACUUM FREEZE ${TABLE_NAME};
В рамках эксперимента ключевые настройки СУБД были умышленно установлены на уровне, недостаточном для штатного функционирования. Данное решение принято для тестирования результатов анализа инцидента СУБД с применением инструкции PG_EXPECTO.
postgres=# show shared_buffers;
shared_buffers
----------------
200MB
(1 row)
postgres=# show work_mem ;
work_mem
----------
16MB
(1 row)
# НАСТРОЙКИ НАГРУЗОЧНОГО ТЕСТИРОВАНИЯ
# Тестовая БД
testdb = default
# Тип синтетической нагрузки
load_mode = olap
# Параметры Пуассоновского распределения
period_hours = -1
average_load = 50
# Имитация инцидента - vacuum
vacuum_incident = 1
# Веса сценариев по умолчанию
scenario1 = 0.7
scenario2 = 0.2
scenario3 = 0.1
# Размер тестовой БД
#~10GB
scale = 685
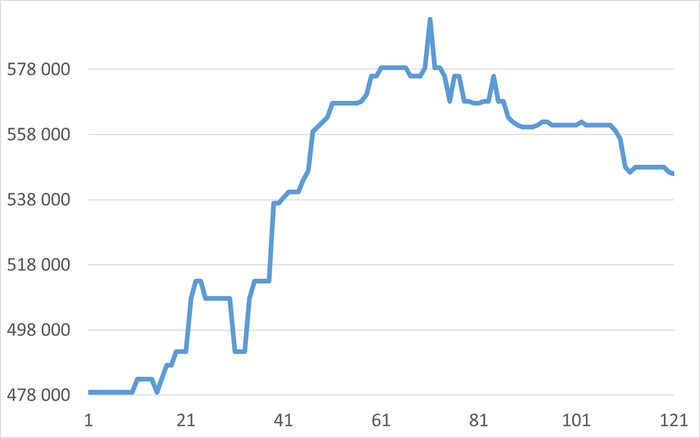
Рис.1 График изменения операционной скорости в процессе инцидента.
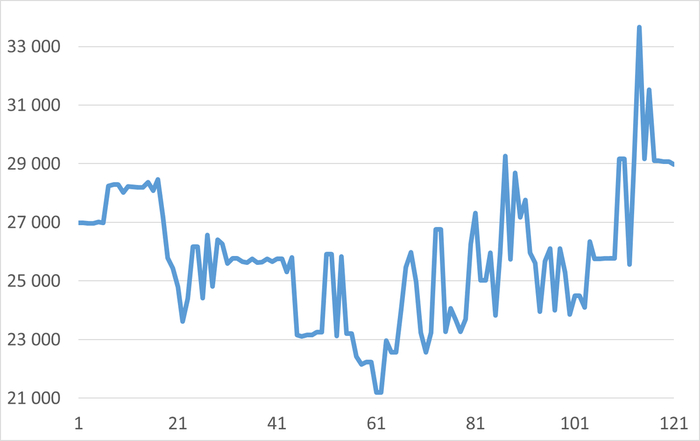
Рис.2 График изменения ожиданий СУБД в процессе инцидента.
Autovacuum работает очень интенсивно (более 170 запусков в час), но удаляет мизерное количество страниц (80–122).
...
Длительность autovacuum в инциденте почти удвоилась (117,7 сек против 61,1 сек) при том же количестве операций – вероятно, из-за возросшей конкуренции за IO или блокировок.
...
За час создаётся ~480 временных файлов общим объёмом ~21 ГБ. Это прямое следствие использования диска для сортировок/хэшей, не помещающихся в work_mem (16 МБ).
...
Диск данных (vdd) – критическая перегрузка: util 100%, задержки чтения/записи >15 мс, очередь >50.
...
RAM (7,5 ГБ) с shared_buffers=200 МБ и effective_cache_size=1 ГБ – возможно, недостаточно для рабочего набора.
Периоды наблюдения:
Тестовый отрезок: 2026-06-05 12:30 – 13:30
Инцидент: 2026-06-05 13:30 – 14:30
Конфигурация:
PostgreSQL 17.5 (Postgres Pro Enterprise), 8 vCPU, RAM 7.5 ГБ
shared_buffers = 200 МБ, effective_cache_size = 1 ГБ, work_mem = 16 МБ
random_page_cost = 1.1 (SSD-ориентированное значение)
checkpoint_timeout = 3600 с, max_wal_size = 4 ГБ, min_wal_size = 2 ГБ
autovacuum включён (workers=4, scale_factor=0.2, analyse_scale_factor=0.005)
vm.dirty_background_ratio = 10%, vm.dirty_ratio = 30%, vm.swappiness = 1
Подтверждено — значение получено из предоставленных метрик или прямого математического следствия.
Вероятно — вывод основан на косвенных признаках, корреляциях или общеизвестных практиках, но не подтверждён прямыми данными.
Предположение — гипотеза, для проверки которой необходимы дополнительные данные либо данные отсутствуют.
Неизвестно — термин или метрика не фигурируют в отчёте, значение неизвестно.
Тезис: Дисковое устройство данных работает на пределе пропускной способности: утилизация 100%, задержки чтения/записи >15 мс, глубина очереди 54–72.
Способ подтверждения: iostat показатели за оба периода: %util = 99,97–99,98%, r_await = 11–20 мс, w_await = 15–16 мс, aqu_sz = 54–72.
Способ опровержения: Если бы %util был ниже 50%, а r_await и w_await <5 мс.
Метка: Подтверждено
Тезис: Ожидания ввода-вывода (IO) остаются критическим фактором в обоих периодах, причём в инциденте их связь с общими ожиданиями стала исключительно сильной (R²=0,92).
Способ подтверждения: В тесте для IO: корреляция 0,7972, R²=0,64; в инциденте: корреляция 0,959, R²=0,92, ВКО 0,84.
Способ опровержения: Если бы в инциденте R² для IO был ниже 0,6 или ВКО ниже 0,2.
Метка: Подтверждено
Тезис: Два конкретных запроса (queryid -76972891903573700 и 7783752063509965868) являются основными источниками IO- и LWLock-ожиданий: на них приходится >97% всех IO-ожиданий.
Способ подтверждения: Диаграммы Парето, где на эти два queryid приходится 65–68% и 32–35% IO-ожиданий соответственно.
Способ опровержения: Если бы распределение ожиданий было равномерным между многими запросами.
Метка: Подтверждено
Тезис: За час создаётся ~480 временных файлов общим объёмом ~21 ГБ – прямое следствие того, что операции сортировки/хэширования не помещаются в work_mem (16 МБ).
Способ подтверждения: temp_files = 479–481, temp_bytes ≈ 21 ГБ/час.
Способ опровержения: Если бы temp_files отсутствовали или объём был менее 1 ГБ/час.
Метка: Подтверждено
Тезис: Время записи контрольной точки (2415–3167 секунд) и синхронизации (540–742 секунды) огромно; контрольные точки запускаются из-за заполнения max_wal_size (4 ГБ), а не по тайм-ауту.
Способ подтверждения: 3–4 checkpoint за час при checkpoint_timeout=3600с (ожидалось 1); длительность записи >> тайм-аута.
Способ опровержения: Если бы время записи было менее 600 секунд и checkpoint запускались только по тайм-ауту.
Метка: Подтверждено
Тезис: Autovacuum запускается более 170 раз в час, но удаляет лишь 80–122 страницы из сотен тысяч оставшихся – параметр scale_factor=0.2 слишком консервативен для больших таблиц.
Способ подтверждения: Оставлено страниц 430 340–450 193, удалено 80–122 (<0,03%).
Способ опровержения: Если бы autovacuum удалял значительную долю мёртвых кортежей.
Метка: Вероятно
Тезис: Очередь процессов на CPU (procs r) стабильно превышает число ядер (8) в 3–4 раза, доля us+sy = 100% времени – хроническая нехватка CPU.
Способ подтверждения: vmstat: procs r = 30–34 (при 8 ядрах), us+sy >80% – 100% периода.
Способ опровержения: Если бы procs r был ниже числа ядер или us+sy <80%.
Метка: Подтверждено
Тезис: Высокая корреляция между context switches и interrupts (r=0,946 в тесте, 0,758 в инциденте) указывает на то, что переключения контекста вызваны прерываниями от дискового IO.
Способ подтверждения: Коэффициенты корреляции и R² из раздела 2.1.
Способ опровержения: Если бы cs коррелировали в основном с us или sy.
Метка: Подтверждено
Тезис: Свободная RAM постоянно менее 5% (100% периода) – это повышает риск отказа в выделении памяти (OOM) и может вызывать рециркуляцию страниц.
Способ подтверждения: free RAM = 128–133 МБ при общей RAM 7,5 ГБ (<5%).
Способ опровержения: Если бы свободной RAM было >10% постоянно.
Метка: Подтверждено
Тезис: Три ошибки lock_not_available (55P03) в инциденте указывают на попытки захвата блокировки, не удавшиеся из-за тайм-аута (deadlock_timeout=1000 мс) – косвенный признак конкуренции за ресурсы.
Способ подтверждения: Лог ошибок за период инцидента.
Способ опровержения: Если бы таких ошибок не было.
Метка: Подтверждено
Тезис: Необходимо получить планы выполнения queryid -76972891903573700 и 7783752063509965868, устранить массовые чтения и записи временных файлов, добавить индексы или переписать запросы.
Способ подтверждения: После оптимизации должно снизиться значение DataFileRead и BuffileWrite в диаграммах Парето.
Способ опровержения: Если после изменений IO-ожидания не уменьшатся.
Метка: Вероятно
Тезис: Увеличить work_mem с 16 МБ до 128–256 МБ (с учётом max_connections=100) для снижения использования temp_files.
Способ подтверждения: Снижение temp_bytes и количества временных файлов.
Способ опровержения: Если temp_files не уменьшатся.
Метка: Вероятно
Тезис: Увеличить max_wal_size до 16–32 ГБ и уменьшить checkpoint_timeout до 900–1800 с, чтобы контрольные точки были более частыми, но менее тяжёлыми.
Способ подтверждения: Снижение времени записи и синхронизации checkpoint, уменьшение max WAL usage.
Способ опровержения: Если время записи останется более 1000 секунд.
Метка: Вероятно
Тезис: Уменьшить autovacuum_vacuum_scale_factor для больших таблиц (например, до 0,05) и увеличить autovacuum_max_workers (до 8).
Способ подтверждения: Увеличение доли удалённых страниц при том же количестве запусков.
Способ опровержения: Если autovacuum продолжит удалять менее 1% оставшихся страниц.
Метка: Вероятно
Тезис: Увеличить shared_buffers с 200 МБ до 1–2 ГБ (25% RAM), а effective_cache_size – до 4–5 ГБ для улучшения кэширования.
Способ подтверждения: Рост hit ratio и снижение DataFileRead.
Способ опровержения: Если hit ratio не изменится или снизится.
Метка: Вероятно
Тезис: Перенести табличное пространство данных на более быстрый диск (NVMe) или выделить отдельный LUN с лучшей IOPS/латентностью; увеличить effective_io_concurrency до 100–200.
Способ подтверждения: Снижение %util, r_await, w_await и aqu_sz по данным iostat.
Способ опровержения: Если задержки и утилизация останутся на прежнем уровне.
Метка: Подтверждено
Тезис: Уменьшить vm.dirty_ratio до 10–15% и vm.dirty_background_ratio до 5%, чтобы снизить накопление грязных страниц и синхронные записи.
Способ подтверждения: Снижение корреляции dirty pages с wa и bo, уменьшение длительности checkpoint.
Способ опровержения: Если dirty pages продолжат достигать 40%+ RAM.
Метка: Вероятно
Тезис: Увеличить RAM до 16–32 ГБ, чтобы рабочий набор данных помещался в кэш страниц и shared_buffers, и всегда был запас свободной памяти.
Способ подтверждения: Снижение свободной RAM <5% более не наблюдается, уменьшение IO-ожиданий.
Способ опровержения: Если после увеличения RAM IO-ожидания не снизятся.
Метка: Вероятно
Тезис: После устранения IO-узких мест, если загрузка CPU останется высокой, увеличить число vCPU или использовать реплики чтения.
Способ подтверждения: После оптимизации запросов и IO показатель procs r станет близким к числу ядер.
Способ опровержения: Если procs r снизится сам собой после других оптимизаций.
Метка: Предположение
Планы выполнения (query plans) для двух проблемных queryid, включая реальное использование памяти, сортировок и хэш-таблиц.
Размеры объектов БД (таблиц, индексов) и количество мёртвых кортежей для оценки эффективности autovacuum.
Логи PostgreSQL за период инцидента для выявления предупреждений (checkpoint occurring too frequently, temporary file size exceeds temp_file_limit и т.п.).
Текущие значения параметров автовакуума для конкретных таблиц (per-table settings).
Статистика по блокировкам (pg_locks, pg_blocking_pids) для анализа lock_not_available.
Данные о сетевой задержке и пропускной способности (если есть удалённые подключения).
Тип и характеристики дискового массива (HDD/SSD, RAID-уровень, общая нагрузка на гипервизоре) для проверки несоответствия random_page_cost=1.1 реальному оборудованию.
Тренды долгосрочной статистики (а не только за 2 часа) для выявления сезонности или постепенной деградации.
В ходе эксперимента с бесконечным пуассоновским потоком сессий и имитацией инцидента VACUUM FREEZE комплекс PG_EXPECTO 10.1.3 позволил корректно и с высокой степенью детализации установить все преднамеренно заложенные дефекты инфраструктуры и конфигурации PostgreSQL.
Аналитический отчёт, сгенерированный инструментом, зафиксировал критическую перегрузку дискового устройства данных (утилизация 99,97–99,98 %, задержки чтения/записи >15 мс, глубина очереди 54–72), что подтверждено метриками iostat; доминирование ожиданий ввода-вывода с коэффициентом детерминации R² = 0,92 в период инцидента; массовое создание временных файлов (около 480 файлов объёмом ~21 ГБ/час) вследствие недостаточного work_mem; аномальную длительность контрольных точек (2415–3167 секунд записи); низкую эффективность автовакуума (более 170 запусков в час при удалении менее 0,03 % мёртвых страниц); хроническую нехватку оперативной памяти (свободно <5 % от 7,5 ГБ) и процессорного времени (очередь на CPU в 3–4 раза превышает число ядер).
Все перечисленные проблемы были выявлены инструментом именно в том составе и с теми количественными характеристиками, которые были заложены в экспериментальную конфигурацию, что подтверждает валидность диагностических алгоритмов PG_EXPECTO.
Представленный эксперимент демонстрирует, что PG_EXPECTO 10.1.3 выступает не только как генератор нагрузки, но и как полноценная платформа для воспроизведения и последующего анализа инцидентов производительности PostgreSQL в контролируемых условиях.
Возможность задания пуассоновского распределения сессий, бесконечного режима тестирования с остановкой по внешнему сигналу и встроенной имитации тяжёлой обслуживающей операции (vacuum freeze) позволяет инженерам по эксплуатации баз данных проактивно выявлять уязвимости конфигурации, узкие места дисковой подсистемы и недостаточность выделенных вычислительных ресурсов.
Полученные результаты подтверждают, что регулярное применение PG_EXPECTO способно служить доказательной базой при оптимизации параметров PostgreSQL и инфраструктурных компонентов.
Дальнейшее развитие комплекса предполагает расширение библиотеки сценариев инцидентов (имитация сетевых задержек, внезапного отказа реплики, всплеска блокировок) и интеграцию с системами мониторинга для автоматизированной оценки эффективности рекомендаций.
Взято с основного технического канала Postgres DBA (Возможны исправления в исходной статье).
Верхний график : индикатор деградации производительности СУБД - подробнее о индикаторе.
Ниже : вероятности текущего прогноза и прогноза на 5 минут о переходе в аварийную ситуацию(начало инцидента) - подробнее о функциях для реализации прогнозов.
Прогноз о переходе в аварийную ситуацию - корректен и оправдался в ходе развития ситуации - что и ожидалось от цепи Маркова.
Использование цепи Маркова для прогнозирования инцидента производительности СУБД PostgreSQL - оправдано и имеет практическое применение.
Работы и исследования - продолжаются.
Работы и исследования - продолжаются.
Взято с основного технического канала Postgres DBA (Возможны исправления в исходной статье).
Первая статья серии исследований о возможности применения цепи Маркова для статистического анализа производительность СУБД PostgreSQL.
1. Цепь Маркова — математическая модель, описывающая последовательность событий, где вероятность перехода из одного состояния в другое зависит только от текущего состояния системы (марковское свойство).
2. Состояние системы — конкретное значение наблюдаемой характеристики в определённый момент времени (например, уровень корреляции между операционной скоростью и количеством ожиданий СУБД).
3. Матрица переходов — квадратная матрица, элементы которой задают вероятности перехода из одного состояния цепи Маркова в другое за один шаг.
4. Корреляция (в контексте СУБД) — статистическая взаимосвязь между двумя показателями производительности ( например операционной скоростью и количеством ожиданий СУБД).
5. Положительная корреляция — ситуация, когда рост одного показателя сопровождается ростом другого (например, при увеличении нагрузки одновременно растут и операционная скорость , и количество ожиданий СУБД — до определённого предела).
6. Отрицательная корреляция — ситуация, когда рост одного показателя сопровождается снижением другого (например, рост ожиданий сопровождается падением операционной скорости — признак исчерпания ресурса).
7. Среднее время до отказа (Mean Time to Failure, MTTF) — прогнозируемое время до наступления критического состояния системы при текущем профиле нагрузки.
8. Экспоненциальное забывание (экспоненциальное сглаживание) — метод адаптации модели, при котором вес старых данных постепенно снижается, а новых — повышается. Позволяет модели адаптироваться к изменениям профиля нагрузки.
9. Стационарность — свойство вероятностных характеристик процесса оставаться неизменными во времени. В контексте цепей Маркова предполагает стабильность вероятностей переходов между состояниями.
10. Скрытая марковская модель (Hidden Markov Model, HMM) — расширение классической цепи Маркова, где наблюдаемые состояния зависят от скрытых (не наблюдаемых напрямую) состояний системы.
11. Дискретизация — процесс преобразования непрерывного диапазона значений в конечное число дискретных состояний (например, разбиение диапазона корреляции на интервалы).
12. Ожидание (wait event) — тип события, которого ждёт обслуживающий процесс, если такое ожидание имеет место.
13. Профиль нагрузки — характеристика рабочей нагрузки на СУБД, включающая типы запросов, их частоту, объём данных и т. п.
14. Предиктивный мониторинг — подход к мониторингу, основанный на прогнозировании будущих состояний системы с использованием математических моделей (в т. ч. цепей Маркова).
15. Адаптивный алертинг — система оповещений, которая автоматически настраивает пороги срабатывания на основе анализа исторических данных и прогнозов.
В нормальном режиме функционирования СУБД корреляция между операционной скоростью и ожиданиями является положительной либо близкой к нулю (в диапазоне от 0 до 1), тогда как отрицательная корреляция, в особенности приближающаяся к –1, представляет собой явный индикатор надвигающегося или уже реализовавшегося инцидента производительности. Исключением выступает случай, когда операционная скорость возрастает, а ожидания снижаются, что также приводит к формированию отрицательной корреляционной связи.
Таким образом, марковская модель на основе коэффициента корреляции становится практически ориентированной: она описывает не просто «напряжение», а вероятность перехода из здорового состояния в аномальное.
Состояние — округлённый до десятичного значения коэффициент корреляции Пирсона между операционной скоростью и ожиданиями СУБД.
🟢В норме корреляция положительная : при штатном росте нагрузки (увеличении числа подключений или частоты запросов) одновременно растёт и скорость, и количество ожиданий СУБД (просто потому, что система выполняет больше работы). Эта прямая зависимость даёт корреляцию в диапазоне от 0 до +1.
Рис.1 Корреляция > 0 , Операционная скорость и Ожидания СУБД - растут.
🟢При снижении нагрузки - операционная скорость снижается , и ожидания СУБД также снижаются. Это также прямая зависимость.
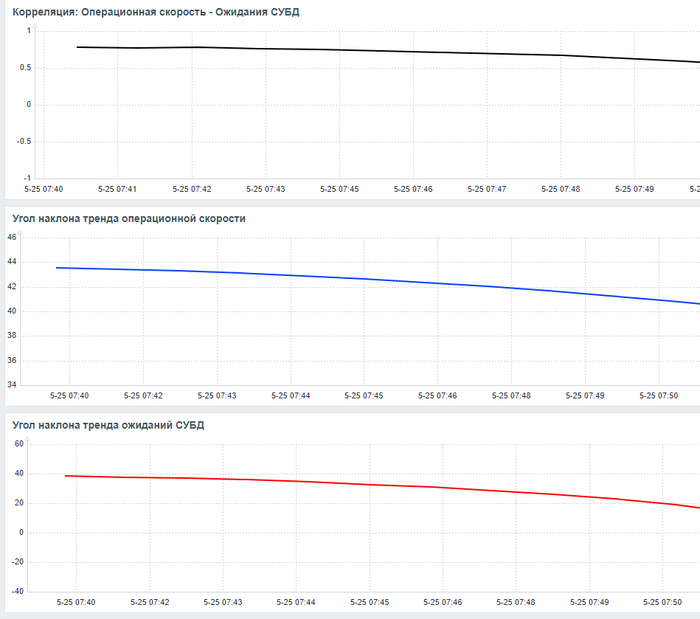
Рис.2 Корреляция > 0 , Операционная скорость и ожидания СУБД - снижаются.
🟢Возможна ситуация - операционная скорость растет и ожидания снижаются . Это штатная ситуация , хотя корреляция будет отрицательной.
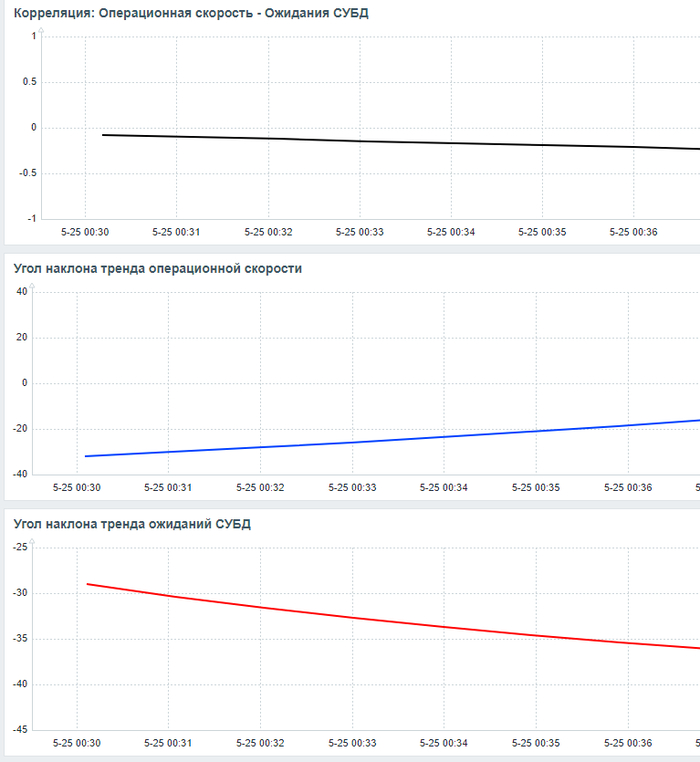
Рис.3 Корреляция < 0 , Операционная скорость - растет , Ожидания СУБД - снижаются.
🟡Но, как только какой-либо ресурс упирается в предел и ожидания начинают «отнимать» скорость, рост ожиданий начинает сопровождаться падением скорости — корреляция становится отрицательной. Именно этот переход и является критическим.
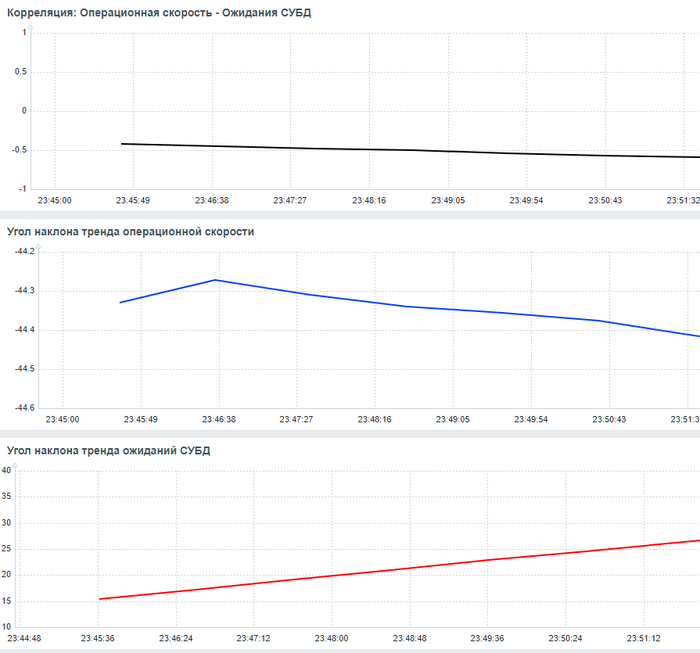
Рис.4 Корреляция < 0 , Операционная скорость снижается, Ожидания СУБД - растут.
Марковская цепь описывает динамику этой связи: вероятности переключения из состояния, например, «+0.4» в «+0.2», а затем в «-0.3».
Отрицательная зона (−1…0) при условии снижения производительности , трактуется как множество аномальных состояний, требующих внимания.
Зная текущее состояние корреляции, модель предсказывает, с какой вероятностью через k шагов система окажется в критической зоне.
Это позволяет вычислить "Среднее время до отказа (Mean Time to Failure, MTTF)" для текущего профиля нагрузки.
Разные типы ожиданий дают разные траектории деградации.
Например:
Переход из «+0.5» в «-0.7» с доминированием IO указывает на дисковое узкое место.
Дрейф в «-0.4» по Lock — на конкурентный доступ.
ℹ️Построение отдельных цепей для каждого класса ожиданий превращает модель в многоканальный детектор первопричин.
Классический мониторинг опирается на фиксированные лимиты (tps < X, время ожидания > Y).
ℹ️Корреляционная марковская модель может сигнализировать о проблеме, когда сами метрики ещё далеки от порогов.
Например, переход из состояния «+0.6» в «+0.2» сам по себе не является аварией, но если матрица показывает, что из «+0.2» с высокой вероятностью следует «-0.5» это даёт запас времени.
Вместо графиков и поиска аномалий в их расхождении, мы получаем одну простую индикаторную панель:
✅«Система в состоянии +0.3 (OK)»,
❗«Система перешла в -0.1 (WARNING)»,
⚠️«Система в -0.8 с вероятностью удержания 0.9 (ALARM)».
Это сильно упрощает как ручную оценку, так и автоматическое принятие решений.
Естественная интерпретация риска: положительная корреляция = норма, отрицательная и снижение производительности = проблема. Модель прямо отражает эту дихотомию.
Проактивность: горизонт предсказания определяется порядком цепи и длиной окна наблюдения, но в любом случае он опережает срабатывание по «сырым» метрикам
Масштабируемость: можно построить отдельные цепи для разных типов ожиданий и даже для комбинаций «скорость – конкретный wait event», создав карту уязвимостей системы.
3.2.1 Марковское свойство и порядок цепи
Динамика корреляции может обладать «инерцией»: значение корреляции не всегда зависит только от предыдущего шага. При 90% времени в положительной зоне это особенно заметно: система может долго флуктуировать около +0.4…+0.6, и нужен критерий значимости перехода. Возможно, потребуется цепь второго порядка или скрытая марковская модель, что усложняет вычисления.
3.2.2. Дискретизация и информативность
Диапазон 0…+1 с шагом 0.1 даёт 11 здоровых состояний. При типовой эксплуатации они все могут быть заселены, но различимость между «+0.3» и «+0.4» может не нести практической ценности.
📋Вместо равномерной дискретизации можно рассмотреть агрегацию:
Зона «Здоровая» (0…+1);
Зона «Неопределённая/предупреждение» (-0.2…+0.1);
Зона «Аварийная» (-1…-0.3).
Это уменьшит размерность матрицы и повысит статистическую надёжность оценок, но может потерять нюанс раннего предупреждения.
3.2.3 Стационарность и адаптация
Распределение нагрузки (дневное/ночное, будни/выходные) меняет характер переходов. Матрица, обученная на дневных данных, может считать переход в «-0.1» аномалией, тогда как в ночное время это нормально из-за снижения общей производительности.
Решения:
1️⃣Хранение и переключение между несколькими моделями по времени/шаблону.
2️⃣Онлайн-адаптация с экспоненциальным забыванием устаревших данных.
С учетом фактического распределения корреляции (90% времени в зоне 0…1) идея становится не просто аналитически любопытной, а практически мощной: марковская цепь прямо моделирует переход «здоровье → болезнь».
ℹ️Это решает ключевую задачу предиктивного мониторинга — раннее обнаружение деградации, выраженное на языке вероятностей.
ℹ️Целесообразность очень высока для систем с чётко выраженными паттернами нагрузки, где допустимы небольшие вложения в нестандартное решение. Модель способна стать основой для адаптивного алертинга с горизонтом предупреждения, который недостижим при анализе только пороговых значений скорости или ожидания.
ℹ️Практическая применимость сдерживается пока только отсутствием готовых инструментов и требованием аккуратной инженерии. Но если рассматривать поэтапное внедрение , это абсолютно реальный путь.
ℹ️Особую ценность модель будет представлять в средах, где инциденты развиваются постепенно, а не возникают мгновенно — тогда прогнозная сила корреляционных переходов проявится максимально.

